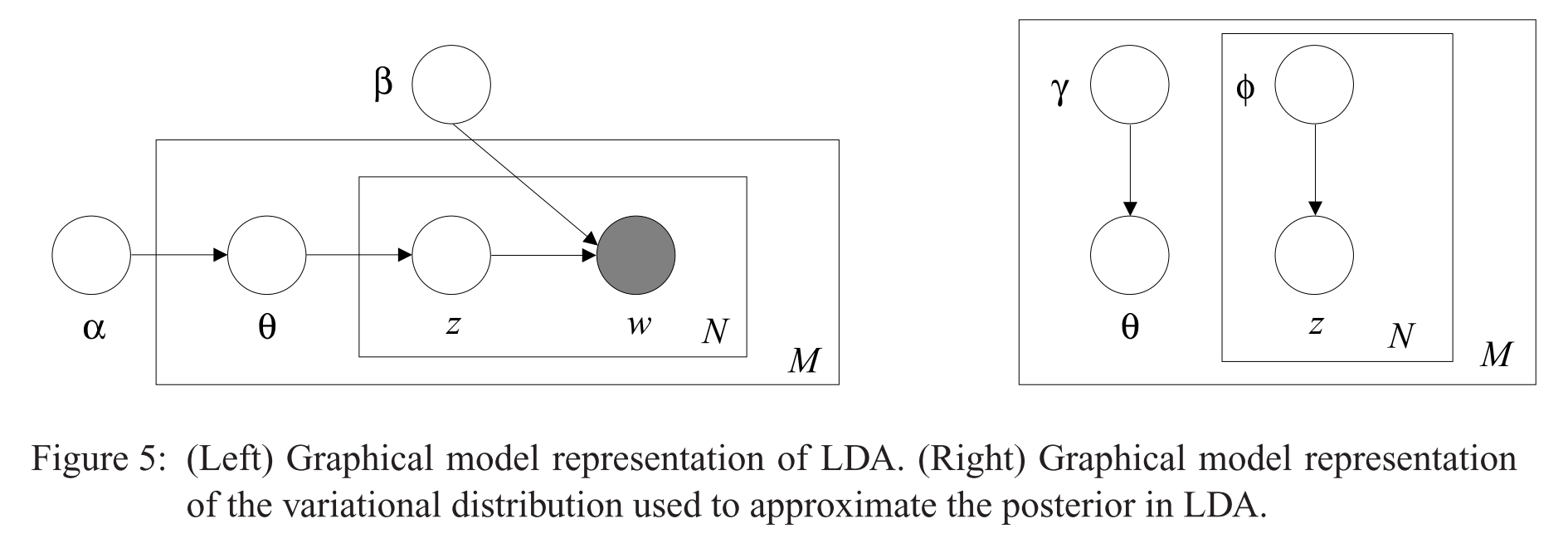
IMHO one of Pyro’s greatest features is the correspondence between the graphical model representation and the code. To implement the guide for the model below (right):
it made sense to me to write the following code:
def guide(data, vocab_size, num_topics):
# not shown in the graphical model
with pyro.plate("topics", num_topics):
lambda_ = pyro.param("lambda", data.new_ones(vocab_size))
beta = pyro.sample("beta", dist.Dirichlet(lambda_))
# shown in the graphical model
with pyro.plate("documents", data.shape[1]):
gamma = pyro.param("gamma", data.new_ones(num_topics))
theta = pyro.sample("theta", dist.Dirichlet(gamma))
with pyro.plate("words", data.shape[0]):
phi = pyro.param("phi", data.new_ones((data.shape[1], num_topics)) / num_topics)
zeta = pyro.sample("zeta", dist.Categorical(phi))
where data is a tensor with dimensions words_per_doc x batch_size.
Let’s look at the first plate. My expectation was that with pyro.plate would build a lambda_ table with dimensions num_topics x vocab_size, exactly as it did with beta. However, that was not the case: beta has num_topics x vocab_size (as I expected), but lambda_ is a simple vector with vocab_size dimensions. Same problem happens with gamma and phi.
Question: Am I doing something wrong or that’s the expected behavior? If the latter is true, wouldn’t be more intuitive to have pyro.param and pyro.sample behaving the same way?
Thanks!
1 Like
see the event_dim arg to param: docs
Thanks @martinjankowiak…
I managed to make the training work, but the posterior predictive doesn’t. I can’t extract the betas. The code complains about memory error, but I suspect the problem is really the dimensions. Code is here.
I tried an even simpler dataset (20 newsgroups) in ProdLDA model implementations. Again, the pure PyTorch implementation yielded better results than port to Pyro. Loss in the former is 100x better than the latter. Really frustrating not knowing why pure PyTorch is better…
Neither LDA with Mean Field approximation nor ProdLDA are working… Don’t know how to move forward…
@carlossouza I’m sorry you’re having trouble. Looking at your code, it looks like you’re not using enumeration for the latent discrete variables (via pyro.infer.TraceEnum_ELBO) or multiple Monte Carlo samples when estimating the ELBO (via the num_particles argument to ELBO implementations), which leads to poor ELBO gradient estimates and probably explains a lot of the low-quality inference results.
Concretely, you might consider decorating both model and guide with config_enumerate and replacing Trace_ELBO() with TraceEnum_ELBO(num_particles=100).
The errors you’re seeing when using Predictive are, as you say, caused by incorrect tensor dimensions. Predictive works by introducing an extra plate dimension to all of the sample sites in your model. As outlined in the tensor shape tutorial, you should be able to resolve these by always writing indexing expressions starting from the rightmost dimension, referring to dimensions with negative indices, and padding with an ellipsis literal, e.g. beta[zeta] -> beta[..., zeta, :].
Interesting… I will try to debug the issue this weekend but in the meantime, could you try
- TraceMeanField_ELBO
- Add normalization constants
log_factorial_n, log_factorial_xs to your recon_loss. I guess this is the main reason for the difference, and this constant difference is not important.
- Use
Multinomial(..., logits=self.decode(theta)) where decode’s output is log_softmax as in your PyTorch implementation (instead of softmax as in your self.recognition_net)
@eb8680_2, @fehiepsi, thanks for your suggestions!!
Here’s the results from some tests:
Changes in Mean Field LDA:
- Write index from the rightmost direction: worked like a charm, great!
- Use TraceMeanField_ELBO: tested with 10 particles instead of 100 (it takes forever even using GPUs), no improvement
- Use TraceEnum_ELBO and config_enumerate: it complains about memory, doesn’t even start…
Changes in ProdLDA:
- TraceEnum_ELBO: tested with 10 particles instead of 100 (it takes forever even using GPUs), eyeballing it may be better (not clear, as numerically the loss is the same)
- Use logits instead of probs in Multinomial, and log_softmax instead of softmax out in the decoder: eyeballing maybe worse (not clear, as numerically the loss is the same)
- Use TraceMeanField_ELBO: just finished testing it, it looks like the best change so far! (numerically the loss is the same, but eyeballing the topics appear to me to be more coherent)
@carlossouza I would not expect TraceEnum_ELBO to have any effect relative to Trace_ELBO in ProdLDA, as there are no discrete latent variables. You should use TraceMeanField_ELBO there, and follow @fehiepsi’s advice to include normalizing constants in your PyTorch likelihood if you want the loss scales to match Pyro.
You’ll need to use TraceEnum_ELBO with multiple particles for your mean-field LDA example, as TraceMeanField_ELBO does not currently support enumeration over discrete variables. The memory error you’re seeing is presumably due to a subtle indexing issue somewhere; I’ll try to run your code and suggest a fix when I have time this week.
1 Like
Yes, I just verified: it looks like TraceMeanField_ELBO yields the best results in ProdLDA… I think I’ll wrap it up with this improvement… I feel I had enough of topic modeling 
1 Like
Would you mind dumping your current, buggy mean-field LDA code into a single script file and opening up a draft pull request so that we can attempt to get it working? No need to turn it into a full-fledged tutorial on top of the ProdLDA one.