posterior.get_samples() returns {'Normal': tensor([0.7652, 0.2905]), 'Uniform': tensor([0.4800, 0.6557])} Why there are no samples from Categorical and Bernoulli? How can I get them?
Hi @odats, I believe the discrete random variables were marginalized out during inference (via enumeration), so they won’t appear in the trace. However I believe you can use Predictive to get the remaining sites (or all sites by setting the return_sites kwarg).
In the documentation I have found TracePredictive (deprecated). Should I sample from Predictive (forward) as an alternative to EmpiricalMarginal?
Let imagine I have obtained posterior P(Z|X). I have a new observation x_11. How to use Predictive to get latent variables Z? There should be something better then Predictive(model_test, posterior.get_samples() + my_new_observation)
That depends on your inference method. If you are using MCMC or standard variational inference (e.g. autoguides), then you will need to re-train on the new data. If you have completely amortized inference you can re-run on the extended data (but in that case I’m not sure Predictive is helpful).
posterior.get_samples() contains samples from posterior (latent variables Z). How should I use these values as a new prior in my model to re-train on the new data? I want to use MCMC to estimate a new posterior P(Z_new|X_new_observations)
there’s no easy way to estimate a new posterior that somehow incorporates information from the old MCMC samples. your best bet in general is to “warm start” the new MCMC chain with a sample from the old chain. you would still need to collect 100s (or more depending on your problem) of samples in the new chain to get good results (at least if you’re keen on closely approximating the true posterior).
Can you please provide some basic code or a link on documentation? I have found only initial_params. I suppose it is the starting point for MCMC and the best option is to set to mean?
It is to help MCMC but not to change prior by learned posterior.
I am more interested in some sort of bayesian online learning. Where I can forget about old data and continuously update my prior by new observations. The closest idea is conjugate prior and sufficient statistics. Where posterior contains all needed information: for example, Beta(a_post, b_post), and then I can use it with new observations.
yes, that looks right. mean, median, final sample all might be reasonable choices—depends on your goals and the problem.
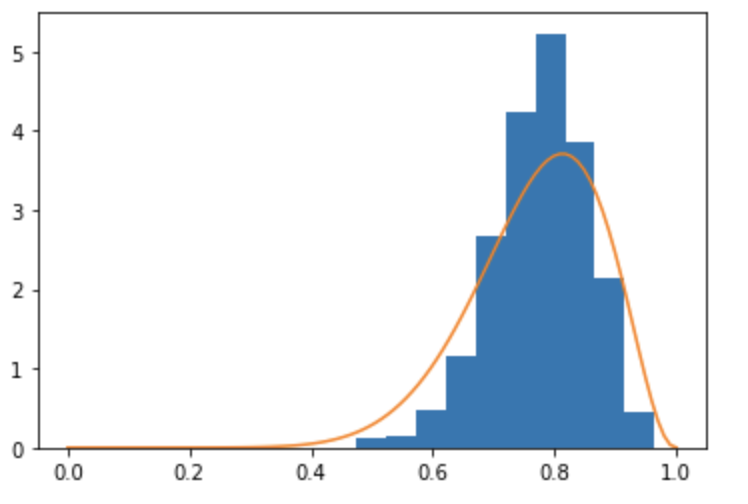
please note that MCMC is “non-parametric” in that it represents the posterior with a bag of samples. in general online learning algorithms have to make parametric assumptions if they want to avoid revisiting old data. the conjugate case you shared is very special—most models are not conjugate. so in most cases you need to make parametric assumptions. one option is variational inference. if you want to stick to MCMC you need to somehow convert your old samples into a density, for example by fitting a mixture distribution to them and using that density as your new prior. whether something like that is likely to work well well depend on the details of your problem, e.g. the dimensionality of the latent space.
no there’s no mechanism to do it automatically since the space of choices is very large. what you’re doing above is using the same parametric family of distributions used in the model (the beta distribution) and choosing a member of that family by maximum likelihood estimation. you could certainly encode that loop in pyro. you can use SVI to do MLE. note that in the general case the prior parametric family is not going to be sufficiently flexible to encode the information in the posterior samples.
i’m not sure i understand your question. yes, it’s the case that variational inference is in general biased and cannot recover the true posterior. this is the consequence of making a parametric approximation.