I took your advice and built my Bayesian NN using TyXe, trained on MNIST. The test set accuracy was around 92%
Next I fed it white noise. My expectation was that if you sample repeatedly for the same image, the output distribution would be uniform - all classes being equally likely to be predicted. But the actual behavior is a but puzzling:
Input:
Output (I take 20 output samples using .predict() and argmax of each of them. The following is the histogram):
The model is very sure the output is a 3!
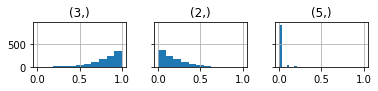
In fact if we repeat this many times (i.e. draw random image, 20 model output samples, histogram of argmax)- over 1000 random samples, we get the following distribution of output classes:
3 appears dominantly, followed by 2 and rarely 5.
Changing the architecture changes the dominant class, say from 3 to 8.
Could you please help explain this counter-intuitive behavior of Bayesian NNs?
i can’t verify if you are using tyxe correctly but i don’t find your results terribly surprising. if some article somewhere has led you to believe that combining the word bayesian with the words neural network magically results in model that “knows when it doesn’t know” then I’m afraid you have been misled. Bayesian neural networks are still an active area of research and it can be difficult to get them to do what you want. when you test on very out of distribution inputs, strange things can happen. better results are likely possible but probably not with the most vanilla approaches.
MNIST digits are binary.
If you show an OOD example with binary features, say FashionMNIST, you will probably get a predictive distribution close to uniform.
But it has been observed that different sources of noise may be fooling networks that are trained outside that range.
Example: if you network has only seen 1 and 0 and now it sees -0.5 it may not be well calibrated for those types of inputs. We also observed that in our GP Hierarchical priors paper, where Gaussian noise as input to an MNIST network was harder to get good OOD estimates for than pretty much anything else we tried that had features closer to MNIST (but with different distributions).
In short: it’s not as unexpected as you might think.
I can only help explain your observation with this empirical observation and my attached hypothesis that the robustness to OOD data obtained by N(0,1) priors and mean field posterior approximations is limited to similar feature spaces with different densities.
Maybe we can find a paper that studies this systematically?