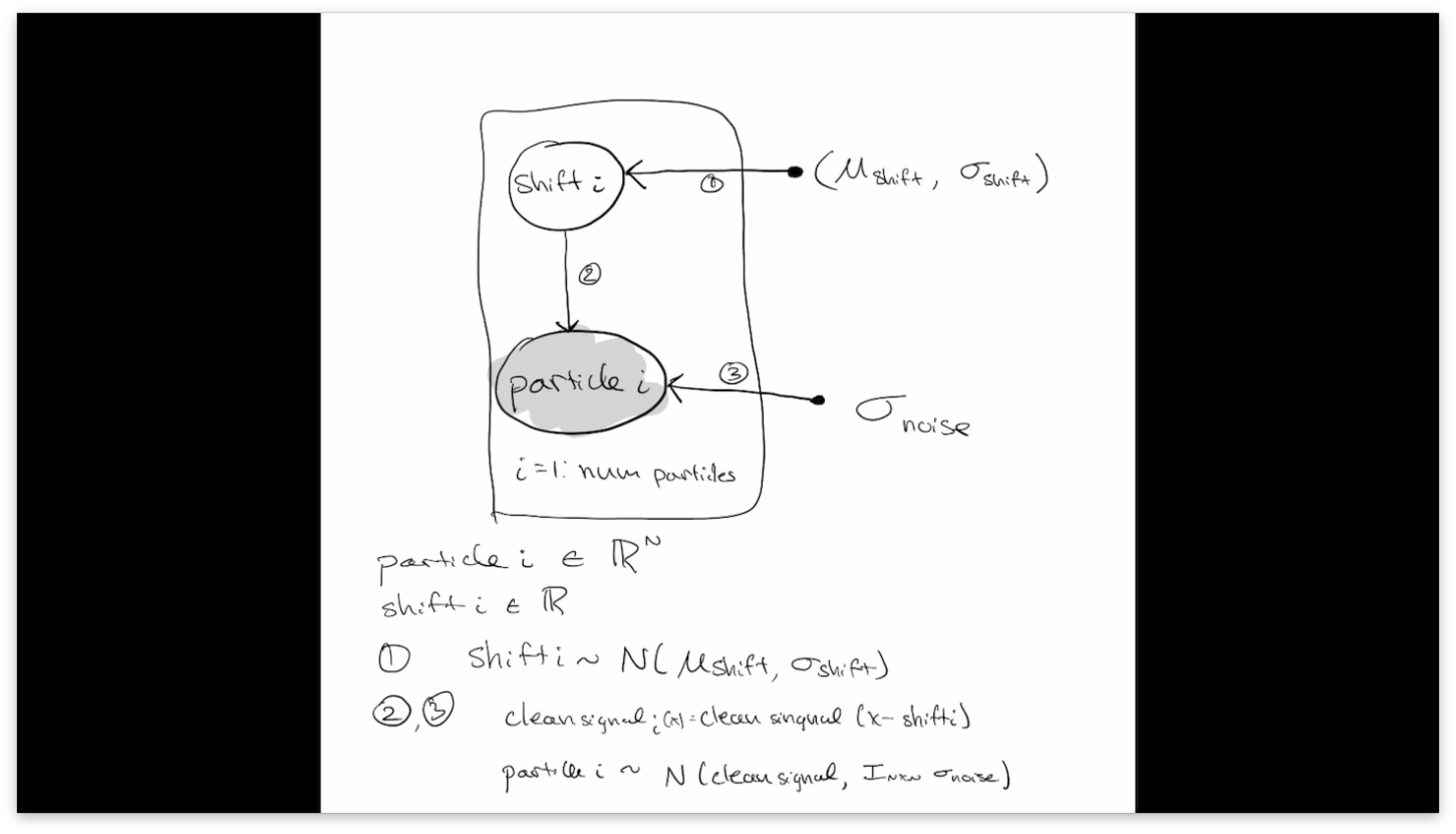
Ok I got the mini batches working with to_event. Predictions match the gt, so the amortization is working: prob_prog/pyro_1D_shift_amortized.ipynb at main · geoffwoollard/prob_prog · GitHub
The issue was a bug in my guide, which was using the wrong data (mlp(one_particle) → mlp(mini_batch))
I like the dim option in pyro.plate. I tried to get that working, but there was some issue with the sizes of shift being (mini_batch,1) in the model vs mini_batch in the guide.
Here we see things working fine with .to_event(1)
mlp = MLP()
do_log=True
def model(mini_batch):
full_size = len(mini_batch)
with pyro.plate('mini_batch',full_size,subsample=mini_batch):
shift = pyro.sample("shift", dist.Normal(0, 2)) # mini batch of different shifts, of size defined by size in pyro.plate(..., size)
if do_log: print('model shift.shape',shift.shape)
if do_log: print('model shift',shift)
clean_signal = torch.exp(-(domain.reshape(1,-1)-shift.reshape(full_size,1))**2/(2*sigma_signal_gt**2)) # mini batch of clean signals, representing a mini batch of noiseless, but shifted particles
if do_log: print('model clean_signal.shape',clean_signal.shape)
with pyro.plate('pixels',num_pix):
distrib = dist.Normal(clean_signal, sigma_noise)
if do_log: print('model particle normal',distrib)
pyro.sample("particle", distrib.to_event(1), obs=mini_batch) # upon each of these noiseless, shifted particles, gaussian noise is added
def guide(mini_batch): # the proposal distribution
"""
mlp will be trained on many particles to predict params of distribution
"""
full_size = len(mini_batch)
pyro.module("mlp", mlp)
with pyro.plate('mini_batch', full_size, subsample=mini_batch):
lam = mlp(mini_batch)
loc, log_scale = lam[:,0], lam[:,1]
scale = torch.exp(log_scale)
distrib = dist.Normal(loc, scale)
if do_log: print('guide shift normal',distrib)
pyro.sample("shift", distrib)
pyro.clear_param_store()
svi = pyro.infer.SVI(model=model,
guide=guide,
optim=pyro.optim.Adam({"lr": 0.03}),
loss=pyro.infer.Trace_ELBO())
losses = []
n_epochs = 1
batch_size = 2
epoch_size = 4#len(data)
for t in range(n_epochs):
random_idx = torch.randperm(num_particles)
permutation = data.index_select(0,random_idx)
for i in range(0,epoch_size, batch_size):
mini_batch = permutation[i:i+batch_size]
losses.append(svi.step(mini_batch))
# guide shift normal Normal(loc: torch.Size([2]), scale: torch.Size([2]))
# model shift.shape torch.Size([2])
# model shift tensor([-0.2310, -0.3911], grad_fn=<AddBackward0>)
# model clean_signal.shape torch.Size([2, 32])
# model particle normal Normal(loc: torch.Size([2, 32]), scale: torch.Size([2, 32]))
# guide shift normal Normal(loc: torch.Size([2]), scale: torch.Size([2]))
# model shift.shape torch.Size([2])
# model shift tensor([1.2149, 0.1887], grad_fn=<AddBackward0>)
# model clean_signal.shape torch.Size([2, 32])
# model particle normal Normal(loc: torch.Size([2, 32]), scale: torch.Size([2, 32]))
And below is the errors I’m seeing with dim in the plates
(input)
mlp = MLP()
do_log=True
def model(mini_batch):
full_size = len(mini_batch)
with pyro.plate('mini_batch',full_size,subsample=mini_batch,dim=-2):
shift = pyro.sample("shift", dist.Normal(0, 2)) # mini batch of different shifts, of size defined by size in pyro.plate(..., size)
if do_log: print('model shift.shape',shift.shape)
if do_log: print('model shift',shift)
clean_signal = torch.exp(-(domain.reshape(1,-1)-shift.reshape(full_size,1))**2/(2*sigma_signal_gt**2)) # mini batch of clean signals, representing a mini batch of noiseless, but shifted particles
if do_log: print('model clean_signal.shape',clean_signal.shape)
with pyro.plate('pixels',num_pix,dim=-1):
distrib = dist.Normal(clean_signal, sigma_noise)
if do_log: print('model particle normal',distrib)
pyro.sample("particle", distrib, obs=mini_batch) # upon each of these noiseless, shifted particles, gaussian noise is added
def guide(mini_batch): # the proposal distribution
"""
mlp will be trained on many particles to predict params of distribution
"""
full_size = len(mini_batch)
pyro.module("mlp", mlp)
with pyro.plate('mini_batch', full_size, subsample=mini_batch):
lam = mlp(mini_batch)
loc, log_scale = lam[:,0], lam[:,1]
scale = torch.exp(log_scale)
distrib = dist.Normal(loc, scale)
if do_log: print('guide shift normal',distrib)
pyro.sample("shift", distrib)
pyro.clear_param_store()
svi = pyro.infer.SVI(model=model,
guide=guide,
optim=pyro.optim.Adam({"lr": 0.03}),
loss=pyro.infer.Trace_ELBO())
losses = []
n_epochs = 1
batch_size = 2
epoch_size = 4#len(data)
for t in range(n_epochs):
random_idx = torch.randperm(num_particles)
permutation = data.index_select(0,random_idx)
for i in range(0,epoch_size, batch_size):
# https://stackoverflow.com/questions/45113245/how-to-get-mini-batches-in-pytorch-in-a-clean-and-efficient-way
mini_batch = permutation[i:i+batch_size]
losses.append(svi.step(mini_batch))
(errors)
guide shift normal Normal(loc: torch.Size([2]), scale: torch.Size([2]))
model shift.shape torch.Size([2])
model shift tensor([0.7913, 0.8643], grad_fn=<AddBackward0>)
model clean_signal.shape torch.Size([2, 32])
model particle normal Normal(loc: torch.Size([2, 32]), scale: torch.Size([2, 32]))
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-229-8ff909300b55> in <module>()
47 # https://stackoverflow.com/questions/45113245/how-to-get-mini-batches-in-pytorch-in-a-clean-and-efficient-way
48 mini_batch = permutation[i:i+batch_size]
---> 49 losses.append(svi.step(mini_batch))
5 frames
/usr/local/lib/python3.7/dist-packages/pyro/util.py in check_model_guide_match(model_trace, guide_trace, max_plate_nesting)
339 raise ValueError(
340 "Model and guide shapes disagree at site '{}': {} vs {}".format(
--> 341 name, model_shape, guide_shape
342 )
343 )
ValueError: Model and guide shapes disagree at site 'shift': torch.Size([2, 1]) vs torch.Size([2])