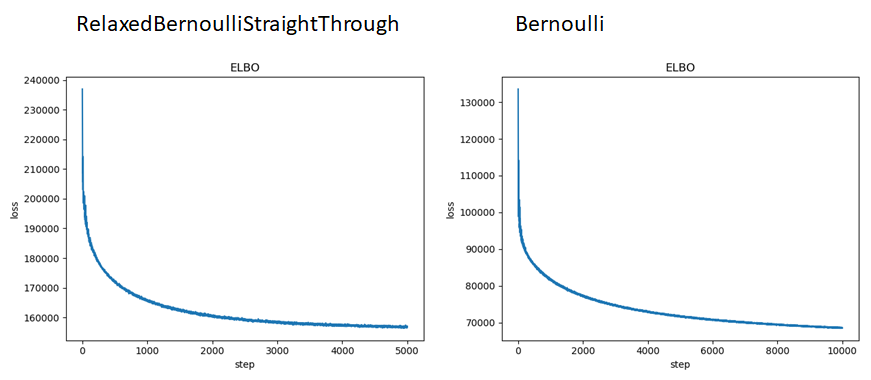
Currently I am working on transforming the Sparse Gamma Deep Exponential Family example, see link. Instead of using Gamma distributions for the weights and latent variables, I’m trying to make a Sigmoid Belief Network (SBN) where the latent variables and weights follow Bernoulli and Normal distributions, respectively. My first attempt with an autoguide has a blog post here, but hasn’t solved my issues. I am now building a custom guide.
My current implementation includes, what I believe, a full reparameterization of all distributions included in the model, that is:
- The top layer of weights,
w_top, is resampled - The bottom layer of weights,
w_bottom, is resampled - The top layer of latent variables,
z_top, is resampled - The bottom layer of latent variables,
z_bottom, is resampled
See also the code on the bottom of this post.
I am confused however that my code won’t run, and crashes because not all distributions in the guide are fully parameterized, or, the following error:
Traceback (most recent call last):
File "C:/Users/posc8001/Documents/DEF/Scipio_DEF/sigmoid_belief_network.py", line 179, in <module>
model = main(args)
File "C:/Users/posc8001/Documents/DEF/Scipio_DEF/sigmoid_belief_network.py", line 158, in main
loss = svi.step(data)
File "C:\Users\posc8001\.virtualenvs\Scipio_DEF-F7b0vflQ\lib\site-packages\pyro\infer\svi.py", line 99, in step
loss = self.loss_and_grads(self.model, self.guide, *args, **kwargs)
File "C:\Users\posc8001\.virtualenvs\Scipio_DEF-F7b0vflQ\lib\site-packages\pyro\infer\trace_elbo.py", line 126, in loss_and_grads
loss_particle, surrogate_loss_particle = self._differentiable_loss_particle(model_trace, guide_trace)
File "C:\Users\posc8001\.virtualenvs\Scipio_DEF-F7b0vflQ\lib\site-packages\pyro\infer\trace_mean_field_elbo.py", line 105, in _differentiable_loss_particle
_check_fully_reparametrized(guide_site)
File "C:\Users\posc8001\.virtualenvs\Scipio_DEF-F7b0vflQ\lib\site-packages\pyro\infer\trace_mean_field_elbo.py", line 39, in _check_fully_reparametrized
raise NotImplementedError("All distributions in the guide must be fully reparameterized.")
NotImplementedError: All distributions in the guide must be fully reparameterized.
Process finished with exit code 1
Does anyone understand what this means and how I should proceed to solve this?
Here is the code that produced the error.
Code:
import os
import sys
import argparse
import numpy as np
import torch
from pathlib import Path
import torch.utils.data
import torch.optim as optim
import pyro
from pyro import poutine
import pyro.optim as optim
from pyro.distributions import Bernoulli, Normal, Beta
from pyro.contrib.autoguide import AutoDiagonalNormal, AutoGuideList, AutoDiscreteParallel
from pyro.infer import SVI, TraceMeanField_ELBO
torch.set_default_tensor_type('torch.FloatTensor')
pyro.enable_validation(True)
pyro.util.set_rng_seed(26011994)
class SigmoidBeliefDEF(object):
def __init__(self):
# define the sizes of the layers in the deep exponential family
self.top_width = 2
self.bottom_width = 3
self.data_size = 5
# define hyperparameters that control the prior
self.p_z = torch.tensor(0.5)
self.mu_w = torch.tensor(0.0)
self.sigma_w = torch.tensor(1.0)
# define parameters used to initialize variational parameters
self.z_mean_init = 0.0
self.z_sigma_init = 3.0
self.w_mean_init = 0.0
self.w_sigma_init = 1.0
self.softplus = torch.nn.Softplus()
# 1
# define the model
def model(self, x):
x_size = x.size(0)
# 1.1
# sample the global weights
with pyro.plate("w_top_plate", self.top_width * self.bottom_width):
w_top = pyro.sample("w_top", Normal(self.mu_w, self.sigma_w))
with pyro.plate("w_bottom_plate", self.bottom_width * self.data_size):
w_bottom = pyro.sample("w_bottom", Normal(self.mu_w, self.sigma_w))
# 1.2
# sample the local latent random variables
# (the plate encodes the fact that the z's for different datapoints are conditionally independent)
with pyro.plate("data", x_size):
z_top = pyro.sample("z_top", Bernoulli(self.p_z).expand([self.top_width]).to_event(1))
# note that we need to use matmul (batch matrix multiplication) as well as appropriate reshaping
# to make sure our code is fully vectorized
w_top = w_top.reshape(self.top_width, self.bottom_width) if w_top.dim() == 1 else \
w_top.reshape(-1, self.top_width, self.bottom_width)
mean_bottom = torch.sigmoid(torch.matmul(z_top, w_top))
z_bottom = pyro.sample("z_bottom", Bernoulli(mean_bottom).to_event(1))
w_bottom = w_bottom.reshape(self.bottom_width, self.data_size) if w_bottom.dim() == 1 else \
w_bottom.reshape(-1, self.bottom_width, self.data_size)
mean_obs = torch.sigmoid(torch.matmul(z_bottom, w_bottom))
# observe the data using a Bernoulli likelihood
pyro.sample('obs', Bernoulli(mean_obs).to_event(1), obs=x)
# 2
# define our custom guide a.k.a. variational distribution.
# (note the guide is mean field)
def guide(self, x):
x_size = x.size(0)
# helper for initializing variational parameters
def rand_tensor(shape, mean, sigma):
return mean * torch.ones(shape) + sigma * torch.randn(shape)
# 2.1
# define a helper function to sample z's for a single layer
def sample_zs(name, width):
p_z_q = pyro.param("p_z_q_%s" % name,
lambda: rand_tensor((x_size, width), self.z_mean_init, self.z_sigma_init))
p_z_q = torch.sigmoid(p_z_q)
poutine.block(pyro.sample("z_%s" % name, Bernoulli(p_z_q).to_event(1)))
# define a helper function to sample w's for a single layer
def sample_ws(name, width):
mean_w_q = pyro.param("mean_w_q_%s" % name, lambda: rand_tensor(width, self.w_mean_init, self.w_sigma_init))
sigma_w_q = pyro.param("sigma_w_q_%s" % name, lambda: rand_tensor(width, self.w_mean_init, self.w_sigma_init))
sigma_w_q = self.softplus(sigma_w_q)
pyro.sample("w_%s" % name, Normal(mean_w_q, sigma_w_q))
# sample the global weights
with pyro.plate("w_top_plate", self.top_width * self.bottom_width):
sample_ws("top", self.top_width * self.bottom_width)
with pyro.plate("w_bottom_plate", self.bottom_width * self.data_size):
sample_ws("bottom", self.bottom_width * self.data_size)
# sample the local latent random variables
with pyro.plate("data", x_size):
sample_zs("top", self.top_width)
sample_zs("bottom", self.bottom_width)
def main(args):
dataset_path = Path(r"C:\Users\posc8001\Documents\DEF\Data\Simulation_1")
file_to_open = dataset_path / "small_data.csv"
f = open(file_to_open)
data = torch.tensor(np.loadtxt(f, delimiter=',')).float()
sigmoid_belief_def = SigmoidBeliefDEF()
# Specify hyperparameters of optimization
learning_rate = 0.2
momentum = 0.05
opt = optim.AdagradRMSProp({"eta": learning_rate, "t": momentum})
# Specify the guide
guide = sigmoid_belief_def.guide
# Specify Stochastic Variational Inference
svi = SVI(sigmoid_belief_def.model, guide, opt, loss=TraceMeanField_ELBO())
# we use svi_eval during evaluation; since we took care to write down our model in
# a fully vectorized way, this computation can be done efficiently with large tensor ops
svi_eval = SVI(sigmoid_belief_def.model, guide, opt,
loss=TraceMeanField_ELBO(num_particles=args.eval_particles, vectorize_particles=True))
# the training loop
for k in range(args.num_epochs):
loss = svi.step(data)
if k % args.eval_frequency == 0 and k > 0 or k == args.num_epochs - 1:
loss = svi_eval.evaluate_loss(data)
print("[epoch %04d] training elbo: %.4g" % (k, -loss))
if __name__ == '__main__':
assert pyro.__version__.startswith('0.3.0')
# parse command line arguments
parser = argparse.ArgumentParser(description="parse args")
parser.add_argument('-n', '--num-epochs', default=1000, type=int, help='number of training epochs')
parser.add_argument('-ef', '--eval-frequency', default=25, type=int,
help='how often to evaluate elbo (number of epochs)')
parser.add_argument('-ep', '--eval-particles', default=20, type=int,
help='number of samples/particles to use during evaluation')
parser.add_argument('--auto-guide', action='store_true', help='whether to use an automatically constructed guide')
args = parser.parse_args()
model = main(args)