As a bit of background, I’m using Pyro to generate a NN that can do Normalizing Flows and have been working on a toy problem to start. A few features in my code that are a departure from the example:
- I have multiple layers and not just one spline. I used a model class that I made to add additional layers (combo of splines [quad, linear], and leaky ReLU functions).
- I manipulated the code a bit to run off the GPU.
As a toy problem I’ve done a base of a normalized gaussian, to a normalized double humped gaussian (i.e. two gaussians added together with different values for \mu and divided by 2 to keep \int_\mathbb{R} p_x(x)\ dx=1 and \int_\mathbb{R} p_z(z)\ dz=1).
In the end, I then get a nice result for the forward direction,
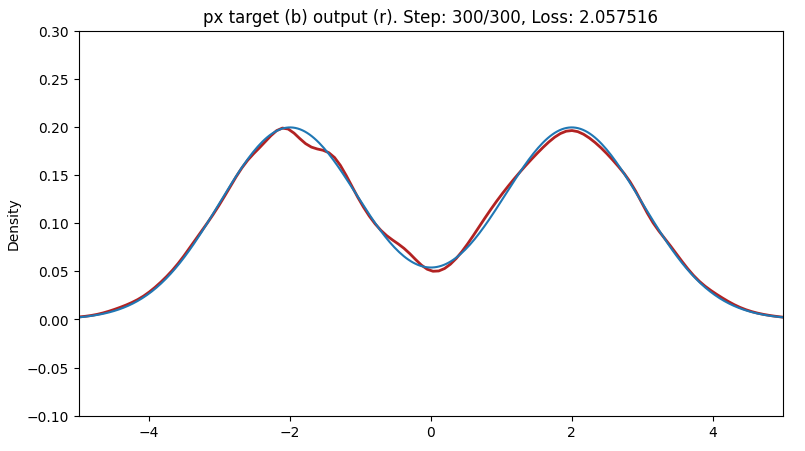
but now I want to go “the other way”, i.e. from the target to the base.
\qquad
\qquad
So my question then: What code do I use to specify that I want flow_dist \rightarrow flow_dist.inverse? In the forward direction I get there by saying:
\qquadflow_dist.sample(torch.Size([1000,]))
which I’m assuming means that it takes 1000 samples from my base distribution (the single hump gaussian distribution) and puts them through the NN to approximate an output of values that when viewed as a KDE look like a double hump gaussian. How then do I do something like:
\qquad flow_dist.inv_sample(torch.Size([1000,]))
which would effectively be taking 1000 samples from the double hump gaussian side, and passing them back through to NN to then approximate the single hump gaussian.
\qquad
\qquad
The main pieces of my code are almost identical to the example on the Pyro norm flows example (2 pieces that don’t follow the example):
-
pseudo_data= randomly generated double hump norm gaussian distributed x datapoints instead of two circles -
transforms= list of parameters from my model class for multiple splines and leaky relu transformations
\qquad
Otherwise:
base_dist = dist.Normal(torch.zeros(1).to(device), torch.ones(1).to(device))
flow_dist = dist.TransformedDistribution(base_dist, transforms)
flow_dist = dist.TransformedDistribution(base_dist, transforms)
dataset = torch.tensor(pseudo_data, dtype=torch.float).to(device)
optimizer = torch.optim.Adam(NormFlowModel.parameters(), lr=LR)
for step in range(steps):
\qquadoptimizer.zero_grad()
\qquadloss = -flow_dist.log_prob(dataset).mean()
\qquadloss.backward()
\qquadoptimizer.step()
Lastly, here’s a link to the code which may be useful given that I had to make a user defined class for the parameters and I manipulated some things to run it off the GPU
Terrible_Code_Written_By_A_Mathematician
Thanks for the help ![]()
-Stefan