we are using a Multimodal Variational Autoencoder inspired by this code and paper to predict conversational engagement (continuous labels between 0 and 1) from facial features and context data eg. binary gender label, numerical personality ratings across five dimensions.
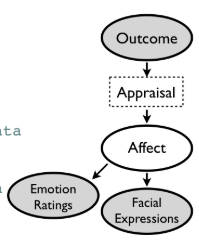
The paper above models the following graph with a Multimodal Variational Autoencoder:
An encoder maps from outcome x to the latent space z, a decoder maps back to outcome. The same happens for facial expressions and emotion ratings, so we can think of it as training three VAEs with a joint latent space. We would like to encode also other causes for emotion ie. instead of modelling continuous outcomes x with a Normal distribution, we model a binary variable x such as gender (male/female) using a Bernoulli distribution. We model the features capturing facial expressions with a Normal distribution, instead of using raw images with the assumption of a Bernoulli distribution as done in the paper.
The Problem: When training the Multimodal VAE, the loss explodes after 6-7 iterations and the weights of the encoder/decoder which map between the binary outcome variable and the latent space z become NaN. This happens even though we clamp the “scale” variable everywhere to prevent them from exploding in the decoder which applies torch.exp() eg.
Q1 Intuitively is there something wrong in the modelling assumptions eg. the Bernoulli assumption for binary outcomes and Normal assumption for visual features like action units?
Q1b How would we model causes that are categorical with more than two possible values?
Q3 Intuitively, what would be sensible priors to set for the role modality and the facial features?
Do you use clamp only in the way you have shown here? If so, you should probably also pass in a maximum value; this use of clamp only provides a lower cutoff to scale. E.g., my_tensor.clamp(min=1e-5, max=1e3). You can still exhibit inf in your tensor if you continue with this usage.
To model categorical variables you could (and maybe even should) use a categorical distribution:
etc. The dirichlet is just a conjugate prior and I am not necessarily recommending that.
3. The modeling assumptions you raised in Q1 seem fine. I have no idea if they actually are fine or not. A bernoulli is kind of what you have to use in order to model binary rvs.
4. The notebook you linked is kind of a nightmare / wall of text and the paper is paywalled. Can you describe what “role modality” and “facial features” are? And then maybe we can figure out some sensible priors.
We also thought about that but didn’t have a good intuition about what makes sense for a max value. Also we tried clamping the values in the forward methods. Unfortunately this didn’t resolve the issue of the weights becoming nan. We found that this behavior can only be postponed by reducing the learning rate. At this point we feel like the weights will become nan at some point it just takes longer to happen with a smaller learning rate.
Thanks for pointing us to the categorical distribution.
Sorry for the paywall paper here ist the link to the arxiv paper. So our initial idea has been to model various context modalities, e.g. role, relationship. In our case the role is basically either 0 or 1 for novices or experts in the dataset. As facial features we considered action units (dim = 17) which are normalized between 0 and 1. Our model consists of multiple encoder decoder pairs for the different modalities. Below is an example for the RoleEncoder where z_dim is the size of the latent space. Regarding the priors we considered N(0.5, 0.1) for the z variable. For Role we used torch.zeros(torch.Size((batch_size, ROLE_VAR_DIM))) + 0.5 as loc.
class RoleEncoder(nn.Module):
def __init__(self, z_dim):
super(RoleEncoder, self).__init__()
self.net = nn.Linear(ROLE_VAR_DIM, 512)
self.z_loc_layer = nn.Sequential(nn.Linear(512, 512),
Swish(),
nn.Linear(512, z_dim))
self.z_scale_layer = nn.Sequential(
nn.Linear(512, 512),
Swish(),
nn.Linear(512, z_dim))
self.z_dim = z_dim
def forward(self, into):
hidden = self.net(into)
z_loc = self.z_loc_layer(hidden)
z_scale = torch.exp(self.z_scale_layer(hidden)).clamp(min=1.0e-5, max=1.0e3)
return z_loc, z_scale
def model(self, relationship=None, role=None, engagement=None, action_units=None, annealing_beta=1.0):
role_prior_loc = torch.zeros(torch.Size((batch_size, ROLE_VAR_DIM))) + 0.5
if role is not None:
with poutine.scale(scale=self.LAMBDA_ROLE):
pyro.sample("obs_role", dist.Bernoulli(role_prior_loc).to_event(1),
obs=role.reshape(-1, ROLE_VAR_DIM))
else:
with poutine.scale(scale=self.LAMBDA_ROLE):
role = pyro.sample("obs_role", dist.Bernoulli(role_prior_loc).to_event(1))
...
...
Following the example notebook this is how we train our model: