Hi,
how can I fit data like this:
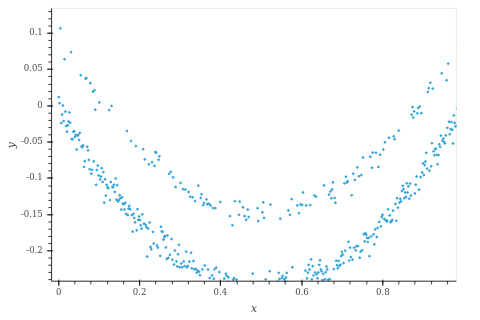
This data was created with:
N = 500
xs = torch.linspace(0, 1, N)
eps = sample('_', dist.Normal(0, 0.01).expand((N, )))
inds = torch.randperm(N)[:N//4]
eps[inds] += 0.1
ys = xs*(xs - 1) + eps
I tried applying the Mixture Model Tutorial and used this model:
from matplotlib import pyplot
from torch import tensor as t
import torch
import pyro
from pyro import sample, distributions as dist, plate, poutine
from pyro.infer import config_enumerate, SVI, TraceEnum_ELBO
from pyro.optim import Adam
from pyro.infer.autoguide import AutoDelta
@config_enumerate
def model(xs, ys):
a = sample('a', dist.Normal(0., 1.))
b = sample('b', dist.Normal(0., 1.))
weights = sample('weights', dist.Dirichlet(t([0.5, 0.5])))
scale = sample('scale', dist.LogNormal(0., 2.))
with plate('comp', 2):
c = sample('c', dist.Normal(0., 1.))
with plate('data', len(xs)):
assignment = sample('assignment', dist.Categorical(weights))
zs = a * xs**2 + b * xs + c[assignment]
pyro.sample('obs', dist.Normal(zs, scale), obs=ys)
return c
K = 2
def init_loc_fn(site):
if site["name"] == "weights":
# Initialize weights to uniform.
return torch.ones(K) / K
if site["name"] == "scale":
return (ys.var() / 2).sqrt()
if site["name"] == "c":
return data[torch.multinomial(torch.ones(len(xs)) / len(xs), K)]
raise ValueError(site["name"])
def initialize(seed):
global global_guide, svi
pyro.set_rng_seed(seed)
pyro.clear_param_store()
global_guide = AutoDelta(poutine.block(model, expose=['weights', 'locs', 'scale']),
init_loc_fn=init_loc_fn)
svi = SVI(model, global_guide, optim, loss=elbo)
return svi.loss(model, global_guide, xs, ys)
optim = pyro.optim.Adam({'lr': 0.01, 'betas': [0.8, 0.99]})
elbo = TraceEnum_ELBO(max_plate_nesting=1)
But the training did not converge.
Thanks in advance.
