So I re-wrote a bit to resemble the model / guide syntax:
def model(idx):
with pyro.poutine.scale(scale=X.size(0) / len(idx)):
X_minibatch = pyro.sample("X", dist.Normal(torch.zeros(len(idx),q), 1)) # prior
y_minibatch = Y[idx]
svgp.set_data(X_minibatch, y_minibatch.T)
svgp.model()
def guide(idx):
x_loc = pyro.param("x_loc", torch.zeros(1000,q))
x_scale = pyro.param("x_scale", torch.ones(1000,q), constraint=constraints.positive)
with pyro.poutine.scale(scale=X.size(0) / len(idx)):
X_minibatch = pyro.sample("X", dist.Normal(x_loc[idx], x_scale[idx])) # guide
y_minibatch = Y[idx]
svgp.set_data(X_minibatch, y_minibatch.T)
svgp.guide()
Let me know if you see anything suspicious here…
dataset_name = 'oilflow'
test_size = 100
n, d, q, X, Y, lb = load_real_data(dataset_name)
Y = Y @ Y.std(axis=0).diag().inverse()
q = 2
# initialize the kernel and model
pyro.clear_param_store()
kernel = gp.kernels.RBF(input_dim=q, lengthscale=torch.ones(q))
likelihood = gp.likelihoods.Gaussian()
latent_prior_mean = torch.zeros(Y.size(0), q)
X_init = float_tensor(PCA(q).fit_transform(Y))
X = torch.nn.Parameter(X_init)
Xu = float_tensor(np.random.normal(size=(25, q)))
optimizer = pyro.optim.Adam({"lr": 0.01})
svgp = gp.models.VariationalSparseGP(X, Y.T, kernel, Xu, likelihood, num_data=X.size(0))
### training with SVI style syntax
svi = SVI(model, guide, optimizer, Trace_ELBO())
svgp.X = pyro.nn.PyroSample(dist.Normal(X_init, 1))
svgp.autoguide('X', dist.Normal)
num_steps = 5000
losses = np.zeros(num_steps)
bar = tqdm(range(num_steps))
for i in bar:
idx = get_batch_idx(Y, 100)
losses[i] = svi.step(idx)
bar.set_description(str(int(losses[i])))
While it runs without errors… I believe it doesn’t recover the batch-less version when I set the idx size to 1000 (so using the full dataset at each step but with set_data).
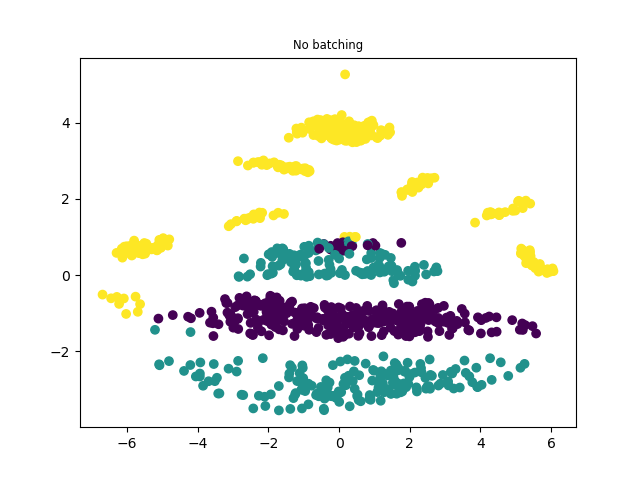
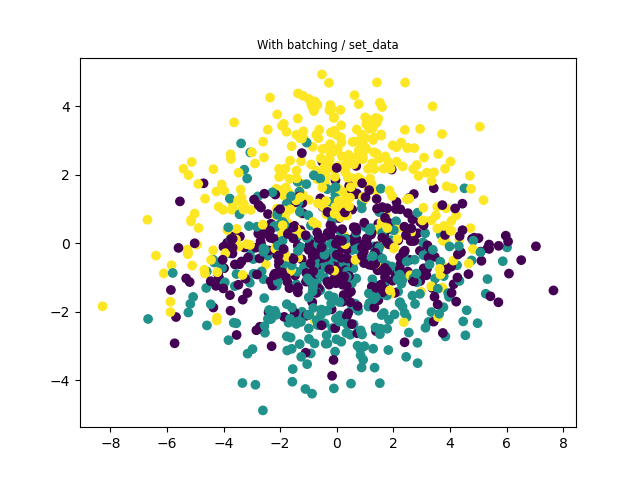
 Also, if you want to optimize the performance, use TraceMeanField_ELBO. It is recommended for GP models.
Also, if you want to optimize the performance, use TraceMeanField_ELBO. It is recommended for GP models.