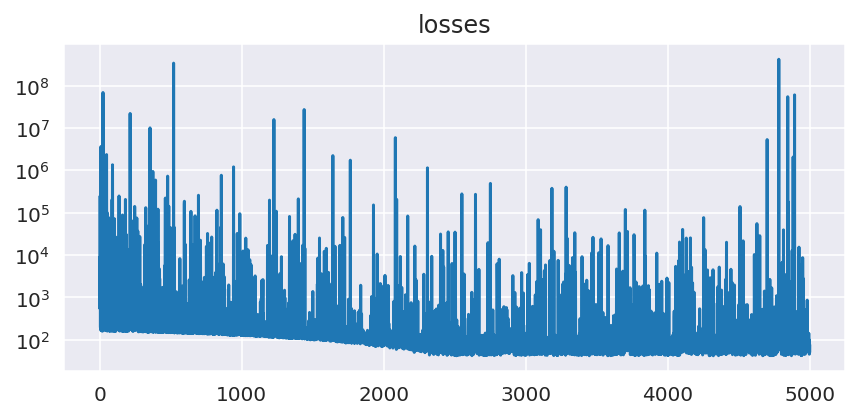
I’m learning how to use the NumPyro SVI API. I’ve followed the Pyro tutorial (I couldn’t find a NumPyro one) and have been trying to fit a simple linear regression example using SVI. I seem to get a good parameter fit, however I was a bit surprised by the variance on the losses:
I’m fairly new to using SVI. I expected some variance on the losses, however I was surprised by how large they were. Is this huge variance to be expected, or if I’m doing something wrong?
Apparently it’s a bad idea to use dist.Exponential as a guide. I switched to dist.LogNormal as the guide for my noise parameter (the noise parameter in the model is still an Exponential) with a much better loss variance, and fit:
I was wondering, is this because the Exponential distribution is Non-reparameterizable? Or is there something else going on?
Is there anywhere to check which NumPyro distributions are non-reparameterizable?
just because you don’t see a visual reduction in variance doesn’t mean there wasn’t a reduction in gradient variance (and therefore probably also) loss variance