Hi everyone!
I’m new to both probabilistic programming and probabilistic machine learning in case you are wondering why I make stupid questions on this forum from time to time 
I’m trying to implement a semi-supervised seq2seq VAE for sequential data by taking inspiration by both your semi-supervised VAE (SS-VAE) and DMM tutorials.
Unfortunately, now I’m stuck in one point of my code and I need, if possible, your help/educated advice.
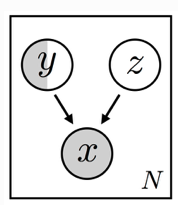
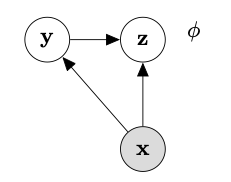
Let me suppose that (part of ) the decoder is a RNN —actually are RNNs also the encoder_z and the encoder_y. The label y is a discrete variable, while z is a continuous one (i.e., a multivariate Gaussian). To avoid any issue due to the high variance of a Monte Carlo estimator for the discrete variable, I decided to use the same solution as in the SS-VAE tutorial, that is that of enumerating y.
A typical approach adopted in seq2seq models relies in concatenating z coming from the encoder_z and y coming from the encoder_y, mapping them into the RNN’s hidden size (e.g., through a MLP) and using it as initial hidden state for the RNN in the decoder, by letting this latter also receive the input x (i.e., some sequence of symbols) during the training.
However, as a consequence of the config_enum setting for the guide (used in conjunction with TraceEnum_ELBO), both y and z (sampled from their respective priors in the model part) have the following shape: y.shape = (num_classes, batch_size, num_classes), and z.shape = (num_classes, batch_size, latent_size). I concatenated z and y, passed the result to an MLP that returned the hidden_state of shape (num_classes, batch_size, hidden_size). At this point I have the doubt on how to proceed. Indeed, the RNN requires that the hidden_state has the shape (1, batch_size, hidden_size) —let me suppose, for the sake of simplicity, that the RNN is not bidirectional and the number of layers is equal to 1.
Thus, which is the more correct way to transform/reshape the hidden_state of shape (num_classes, batch_size, hidden_size) into the correct shape (1, batch_size, hidden_size) required to be fed into the RNN inside the decoder?
I hope that I was able to describe my doubt, even without using code snippets.
Thank you in advance for your help!