I am using Pyro to implement a complex dynamic topic model. AutoGuide does not seem to work for my model, so I chose to write the guide manually. I wrote the variational distribution of the model, which follows the mean-field assumption (variables with subscripts k,i,d are all local conditional independent random variables).


However, implementing this mean-field variational distribution manually seems to be complicated because, for each local conditional independent random variable, I need to specify an independent variational parameter for it, which leads to a large number of variational parameters in the guide.
def _manual_guide(self):
"""
(Core) Implements the `guide` structure of a Pyro model
Returns:
_type_: _description_
"""
# subsample size
if self._subsample_size is None:
user_subsample_size = self.obs_params["I"]
else:
user_subsample_size = self._subsample_size["I"]
# learnable parameters
# univariate params
delta_k_loc = pyro.param(f"delta_k_loc", lambda: self._guide_prior["delta_k_loc"])
delta_k_scale = pyro.param(f"delta_k_scale",
lambda: self._guide_prior["delta_k_scale"],
constraint=constraints.greater_than(0.))
delta_kappa_loc = pyro.param(f"delta_kappa_loc", lambda: self._guide_prior["delta_kappa_loc"])
delta_kappa_scale = pyro.param(f"delta_kappa_scale",
lambda: self._guide_prior["delta_kappa_scale"],
constraint=constraints.greater_than(0.))
delta_rho_loc = pyro.param(f"delta_rho_loc", lambda: self._guide_prior["delta_rho_loc"])
delta_rho_scale = pyro.param(f"delta_rho_scale",
lambda: self._guide_prior["delta_rho_scale"],
constraint=constraints.greater_than(0.))
mu_mu_kappa = pyro.param("mu_mu_kappa", lambda: self._guide_prior["mu_mu_kappa"])
Sigma_mu_kappa = pyro.param("Sigma_mu_kappa",
lambda: self._guide_prior["Sigma_mu_kappa"],
constraint=constraints.positive_definite)
n_Lambda_kappa = pyro.param("n_Lambda_kappa",
lambda: self._guide_prior["n_Lambda_kappa"],
constraint=constraints.positive)
V_Lambda_kappa = pyro.param("V_Lambda_kappa",
lambda: self._guide_prior["V_Lambda_kappa"],
constraint=constraints.positive_definite)
# Multivariate params
kappa_mu = [] # (I, K)
kappa_Sigma = [] # (I, K)
gamma_mu = [] # (D, I, K)
gamma_sigma = [] # (D, I, K)
eta = [] # (K, V)
rho_loc = [] # (K, X)
rho_scale = [] # (K, X, X)
alpha_loc = [] # (K, K)
alpha_scale = [] # (K, K, K)
beta_loc = [] # (K, K)
beta_scale = [] # (K, K, K)
tau_a = [] # (K, )
tau_b = [] # (K, )
for i in range(self.obs_params["I"]):
# kappa_mu, kappa_Sigma
kappa_mu_i = pyro.param(f"kappa_mu_{i}", lambda: self._guide_prior["kappa_mu"])
kappa_Sigma_i = pyro.param(f"kappa_Sigma_{i}",
lambda: self._guide_prior["kappa_Sigma"],
constraint=constraints.positive_definite)
kappa_mu.append(kappa_mu_i)
kappa_Sigma.append(kappa_Sigma_i)
# gamma_mu, gamma_sigma
for d in range(self.obs_params["document_sequence_length"]):
gamma_mu_d = []
gamma_sigma_d = []
for i in range(self.obs_params["I"]):
gamma_mu_id = pyro.param(f"gamma_mu_{i}_{d}", lambda: self._guide_prior["gamma_mu"]) # (K, )
gamma_sigma_id = pyro.param(f"gamma_Sigma_{i}_{d}",
lambda: self._guide_prior["gamma_Sigma"],
constraint=constraints.positive) # (K, )
gamma_mu_d.append(gamma_mu_id)
gamma_sigma_d.append(gamma_sigma_id)
gamma_mu.append(gamma_mu_d)
gamma_sigma.append(gamma_sigma_d)
for k in range(self.obs_params["K"]):
eta_k = pyro.param(f"eta_{k}", lambda: self._guide_prior["eta_v"], constraint=constraints.positive)
eta.append(eta_k)
rho_loc_k = pyro.param(f"rho_loc_{k}", lambda: self._guide_prior["rho_loc"])
rho_scale_k = pyro.param(f"rho_scale_{k}",
lambda: self._guide_prior["rho_scale"],
constraint=constraints.positive)
rho_loc.append(rho_loc_k)
rho_scale.append(rho_scale_k)
alpha_loc_k = pyro.param(f"alpha_loc_{k}", lambda: self._guide_prior["alpha_loc"])
alpha_scale_k = pyro.param(f"alpha_scale_{k}",
lambda: self._guide_prior["alpha_scale"],
constraint=constraints.positive)
alpha_loc.append(alpha_loc_k)
alpha_scale.append(alpha_scale_k)
beta_loc_k = pyro.param(f"beta_loc_{k}",
lambda: self._guide_prior["beta_loc"],
constraint=constraints.greater_than(1.))
beta_scale_k = pyro.param(f"scale_beta_{k}",
lambda: self._guide_prior["beta_scale"],
constraint=constraints.positive)
beta_loc.append(beta_loc_k)
beta_scale.append(beta_scale_k)
tau_a_k = pyro.param(f"tau_a_{k}",
lambda: self._guide_prior["tau_a"],
constraint=constraints.greater_than(0.))
tau_b_k = pyro.param(f"tau_b_{k}",
lambda: self._guide_prior["tau_b"],
constraint=constraints.greater_than(0.))
tau_a.append(tau_a_k)
tau_b.append(tau_b_k)
# global RV
q_delta_k = pyro.sample(f"delta_k", dist.Normal(delta_k_loc, delta_k_scale))
q_delta_kappa = pyro.sample(f"delta_kappa", dist.Normal(delta_kappa_loc, delta_kappa_scale))
q_delta_rho = pyro.sample(f"delta_rho", dist.Normal(delta_rho_loc, delta_rho_scale))
q_mu_kappa = pyro.sample("mu_kappa", dist.MultivariateNormal(mu_mu_kappa, Sigma_mu_kappa))
q_Lambda_kappa = pyro.sample("Lambda_kappa", dist.Wishart(n_Lambda_kappa, V_Lambda_kappa))
kappa_mu = torch.stack(kappa_mu)
kappa_Sigma = torch.stack(kappa_Sigma)
with pyro.plate("kappa_plate", self.obs_params["I"], dim=-1):
q_kappa = pyro.sample("kappa", dist.MultivariateNormal(kappa_mu, kappa_Sigma))
q_gamma = []
eta = torch.stack(eta)
rho_loc = torch.stack(rho_loc)
rho_scale = torch.stack(rho_scale)
alpha_loc = torch.stack(alpha_loc)
alpha_scale = torch.stack(alpha_scale)
beta_loc = torch.stack(beta_loc)
beta_scale = torch.stack(beta_scale)
tau_a = torch.stack(tau_a)
tau_b = torch.stack(tau_b)
with pyro.plate("topic_plate", self.obs_params["K"], dim=-1):
q_varphi = pyro.sample(f"varphi", dist.Dirichlet(eta))
q_rho = pyro.sample(f"rho", dist.MultivariateNormal(rho_loc, rho_scale))
q_alpha = pyro.sample(f"alpha", dist.MultivariateNormal(alpha_loc, alpha_scale))
q_beta = pyro.sample(f"beta", dist.MultivariateNormal(beta_loc, beta_scale))
q_tau = pyro.sample(f"tau", dist.Gamma(tau_a, tau_b))
with pyro.plate("user_plate", self.obs_params["I"], dim=-2):
for d in range(self.obs_params["document_sequence_length"]):
q_gamma_d = pyro.sample(f"gamma_{d}",
dist.Normal(torch.stack(gamma_mu[d]),
torch.stack(gamma_sigma[d]))) # (I, K)
q_gamma.append(q_gamma_d)
q_gamma = torch.stack(q_gamma)
q_theta = F.softmax(q_gamma, dim=-1)
with pyro.plate("user_plate_2", self.obs_params["I"], subsample_size=user_subsample_size,
dim=-1) as u_ind_word_guide: # I
u_ind_word_guide = u_ind_word_guide.to(self.device)
with pyro.plate("document_sequence", self.obs_params["document_sequence_length"], dim=-2): # D
with pyro.plate("document", self.obs_params["document_length"], dim=-3): # N
word_topic = pyro.sample(f"word_topic",
dist.Categorical(q_theta.index_select(1, u_ind_word_guide)),
infer={"enumerate": "parallels"}) # (N, D, I)
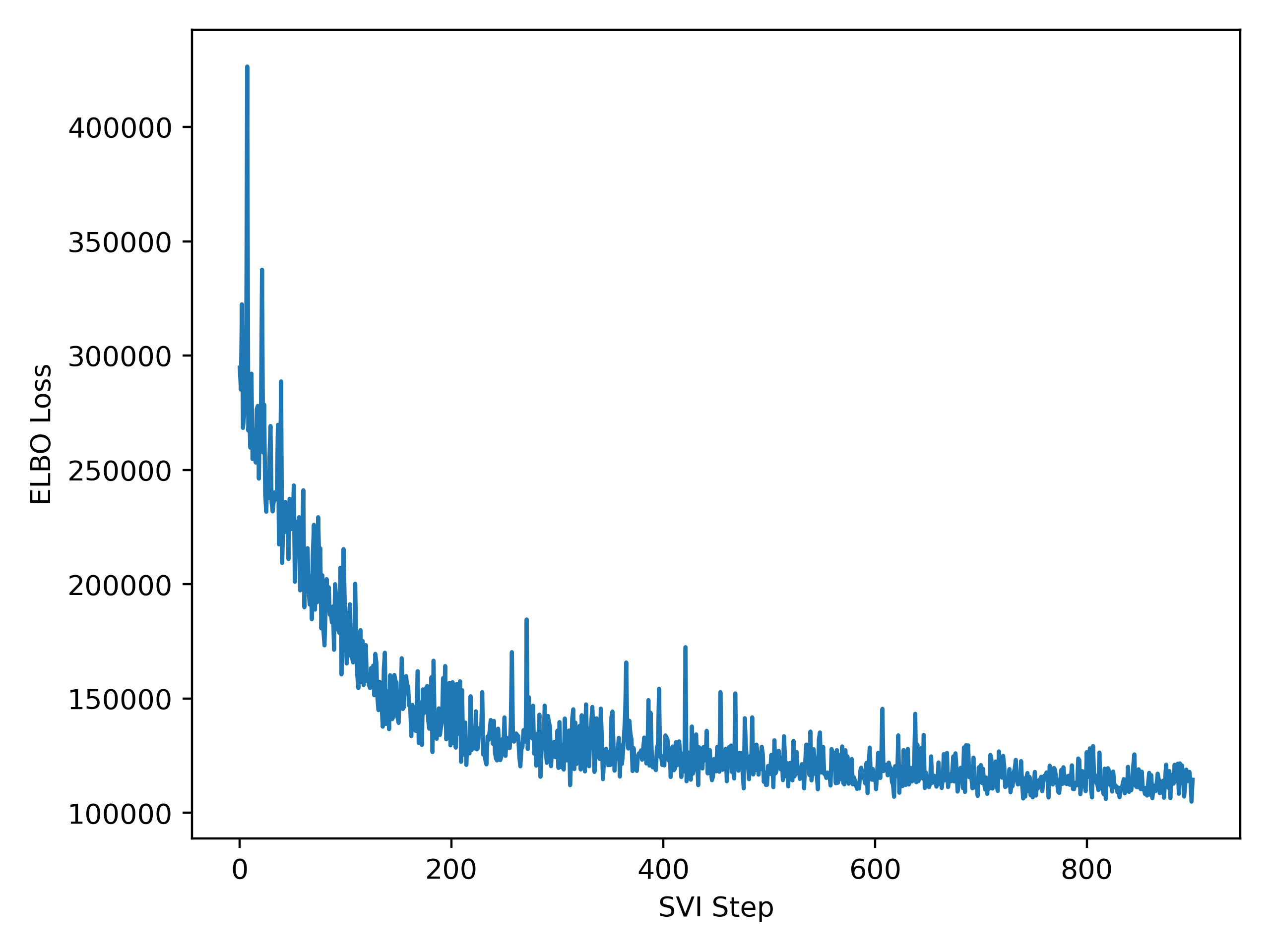
Currently, my model can run successfully, but the results do not seem to be as good as expected. I am confused about whether my understanding of the manually written guide is correct.