Hello,
I’m having a “Memory Exhausion” issue:
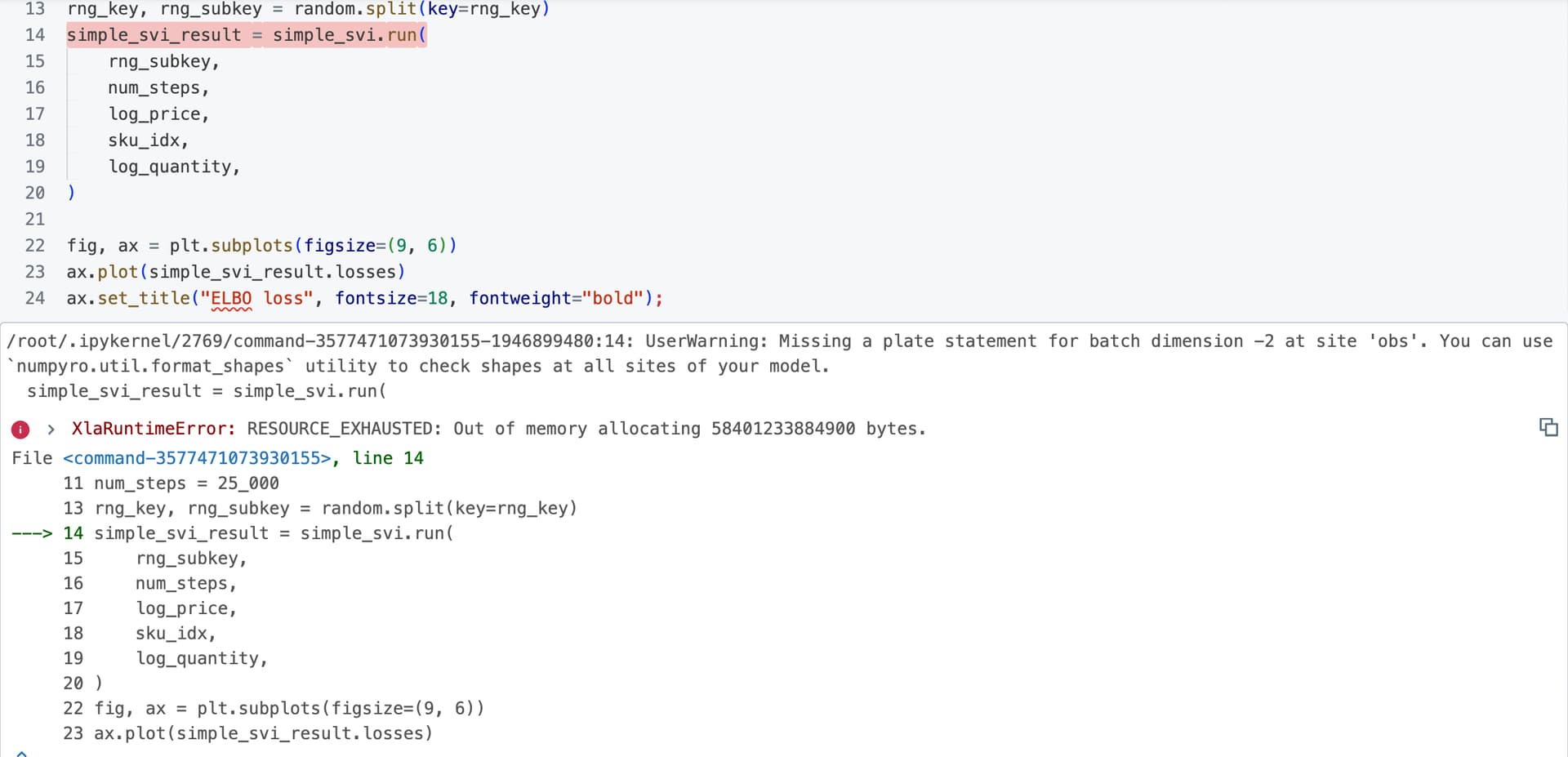
Is there a way to reduce the usage of memory of the algorithm? (Some sort of batch_size?)
Thanks in advance
Hello,
I’m having a “Memory Exhausion” issue:
Is there a way to reduce the usage of memory of the algorithm? (Some sort of batch_size?)
Thanks in advance
without further information about your model (and ideally some code) i’m afraid it’s impossible to answer here
I’m using a code from the internet is this:
def simple_elasticity_model(log_price, sku_idx, log_quantity=None):
n_obs = log_price.size
n_sku = np.unique(sku_idx).size
with numpyro.plate("sku", n_sku):
sku_intercept = numpyro.sample("sku_intercept", dist.Normal(loc=0, scale=1))
beta_log_price = numpyro.sample("beta_log_price", dist.Normal(loc=0, scale=1))
sigma_sku = numpyro.sample("sigma", dist.HalfNormal(scale=1))
mu = beta_log_price[sku_idx] * log_price + sku_intercept[sku_idx]
sigma = sigma_sku[sku_idx]
with numpyro.plate("data", n_obs):
numpyro.sample("obs", dist.Normal(loc=mu, scale=sigma), obs=log_quantity)
Then the training step:
simple_guide = AutoNormal(simple_elasticity_model)
simple_optimizer = numpyro.optim.Adam(step_size=0.01)
simple_svi = SVI(
simple_elasticity_model,
simple_guide,
simple_optimizer,
loss=Trace_ELBO(),
)
num_steps = 25_000
rng_key, rng_subkey = random.split(key=rng_key)
simple_svi_result = simple_svi.run(
rng_subkey,
num_steps,
log_price,
sku_idx,
log_quantity,
)
fig, ax = plt.subplots(figsize=(9, 6))
ax.plot(simple_svi_result.losses)
ax.set_title("ELBO loss", fontsize=18, fontweight="bold");
That is all I have of the model.
you can do mini-batching by using the subsample_size arg in your plate(s), see e.g. here
I changed it to 1:
def simple_elasticity_model(log_price, sku_idx, log_quantity=None):
n_obs = log_price.size
n_sku = np.unique(sku_idx).size
with numpyro.plate("sku", n_sku, subsample_size=1):
sku_intercept = numpyro.sample("sku_intercept", dist.Normal(loc=0, scale=1))
beta_log_price = numpyro.sample("beta_log_price", dist.Normal(loc=0, scale=1))
sigma_sku = numpyro.sample("sigma", dist.HalfNormal(scale=1))
mu = beta_log_price[sku_idx] * log_price + sku_intercept[sku_idx]
sigma = sigma_sku[sku_idx]
with numpyro.plate("data", n_obs):
numpyro.sample("obs", dist.Normal(loc=mu, scale=sigma), obs=log_quantity)
But I’m getting the same error, is there another way to control the amount of data the model is receiving.
its probably the second plate that is the issue. see SVI Part II: Conditional Independence, Subsampling, and Amortization — Pyro Tutorials 1.9.1 documentation
Martin is probably right about the all-data likelihood causing the crash. If you still run into memory issues when using the indices from plate('data', n_obs, subsample_size=k) for k<<n_obs you should have a look at dataloaders in Jax: Training a simple neural network, with tensorflow/datasets data loading — JAX documentation. You will still need to do the appropriate likelihood scaling either using the plate or manually using handlers.scale. See SVI Part II that Martin linked.