Thank you very much for your reply @martinjankowiak I’m sorry for my late response.
I’ve read the post you mentioned (and other posts about customizing the loss like cunstom loss ).
From the post you pointed to me, I understand that paramteres that are optimized by Adam are unconstrained, and then they are mapped to constrained space. Since I’m using autoguide, I cannot get constrained parameters using pyro.param(...) . But I found that pyro.get_param_store().values() can return both constarined and unconstrained parameters from autoguide. So I extracted the constained parameters from pyro.get_param_store().values() to calculate my loss function and throw unconstrained parameneters from list(guide.parameters() to Adam. However this result doesn’t make sense.
Below is my example of estimating slope and intercept from a simple linear regression. It would be highly appreciated if you could take a look.
import torch
import pyro
import numpy as np
from pyro.optim import Adam
from pyro.infer.autoguide import AutoNormal
import pyro.distributions as dist
from pyro import poutine
from pyro.infer import SVI, Trace_ELBO
from pyro.ops.special import safe_log
from matplotlib import pyplot as plt
np.random.seed(0)
xtest = torch.tensor([2.,4.,5.,6.,8.],dtype = torch.float32)
ytest = 2*xtest +8
def model(xtest,ytest):
slope = pyro.sample('slope', dist.Uniform(0,10))
intercept = pyro.sample('intercept', dist.Uniform(0,10))
locs = xtest *slope + intercept
with pyro.plate('data', len(xtest)):
pyro.sample('obs', dist.Normal(locs,0.2), obs=ytest)
def my_loss(guide):
constrained_params = list(pyro.get_param_store().values())
slope = constrained_params[1]
intercept = constrained_params[3]
preds = slope * xtest + intercept
y = ytest
SSE = torch.sum(torch.square(preds - y))
return SSE
pyro.set_rng_seed(0)
pyro.clear_param_store()
guide = AutoNormal(model)
guide_init = guide(xtest,ytest)
optimizer = torch.optim.Adam(list(guide.parameters()), lr=0.005)
losses = []
n = 1000
for i in range(n):
loss = my_loss(guide)
loss.backward()
optimizer.step()
optimizer.zero_grad()
losses.append(float(loss.detach().numpy()))
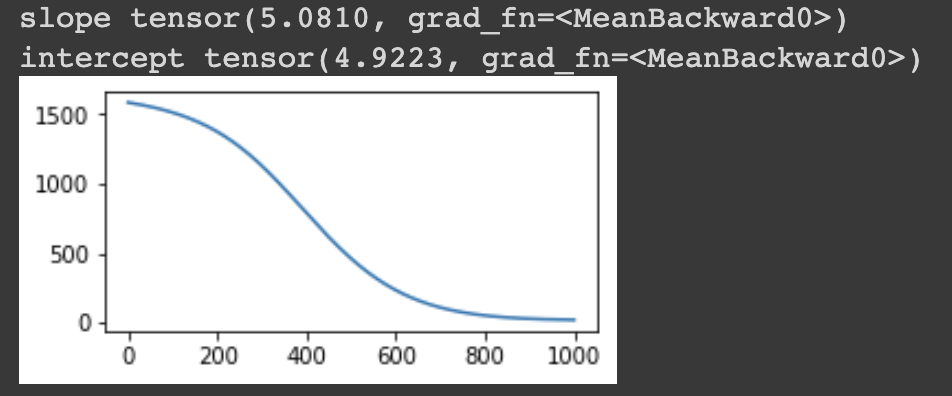
plt.figure(figsize=(14, 7))
plt.plot(losses)
with pyro.plate('samples', 2000, dim=-1):
svi_samples = guide(xtest,ytest)
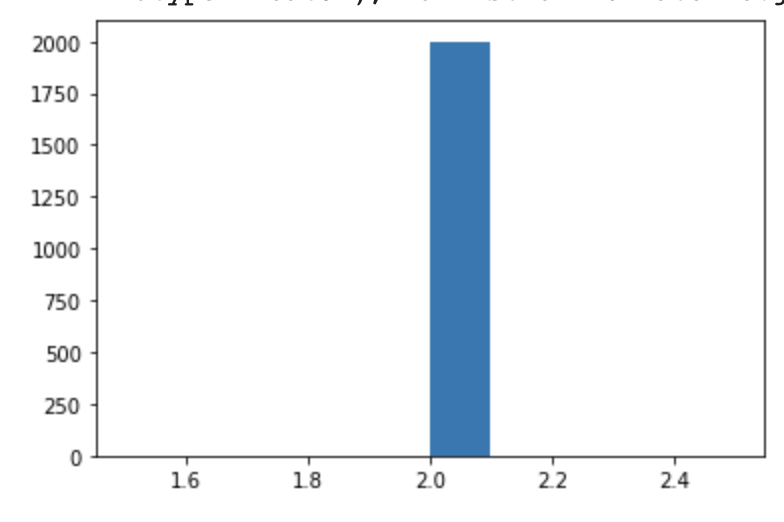
print('slope',torch.mean(svi_samples['slope']))
print('intercept',torch.mean(svi_samples['intercept']))
It seems that it’s converging, however, the estimation of the variables make no sense since they’re simply the avarage of the uniform bound (0+10)/2. The ground truth should be 2 and 8 respectively.
Thus I’m assuming the way I got constained parameters is wrong. I’m wondering how to extract constrained parameters from the autoguide to define my new loss function? Or alternatively, how to extract model fitted values f(x) directly in order to define my new loss function (SSE =sum (f(x)-yobs))^2?
Thank you a lot