Hello all,
I am trying out Numpyro hoping I will be able to use it on GPU with (relatively) large dataset. I also hope to be able to use Funsor-based enumeration.
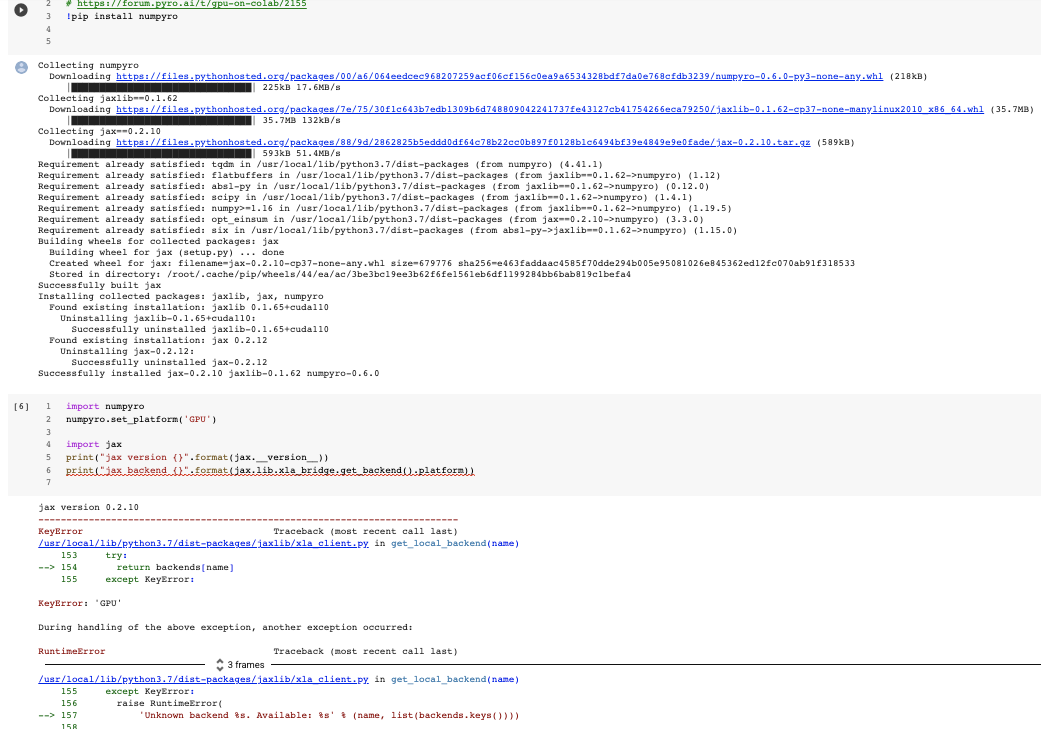
I want to run it on Colab so I choose gpu-backed runtime and install the packages by doing the following:
!pip install numpyro
!pip install funsor
Then I load the packages and check jax’s device:
import jax
import numpyro
import funsor
from jax.lib import xla_bridge
print(xla_bridge.get_backend().platform)
Unfortunately it shows “cpu”. Dou you know how to enable gpu for jax in colab?
Many thanks,
Szymon
Hi @Elchorro, you can use numpyro.set_platform to either using CPU, GPU, or TPU on colab. For cloud TPU, you need some extra configs as in jax demo.
2 Likes
I tried this, but it did not work.
I get the error Unknown backend GPU. Available: ['interpreter', 'cpu']
The problem seems to be that pip install numpyro causes this to happen: Uninstalling jaxlib-0.1.65+cuda110. The cuda version of jax (built in to colab) gets removed and replaced with a CPU version: Successfully installed jax-0.2.10 jaxlib-0.1.62 numpyro-0.6.0
@murphyk Currently, we pin jax/jaxlib versions in each release. From the next release, we’ll relax that restriction. For now, the simplest way is to add
!pip install -q numpyro@git+https://github.com/pyro-ppl/numpyro
to the top of your colab notebook, like bayesian regression tutorial
Thanks, that is much simpler and faster 
I use this idiom to install numpyro in colab:
!pip install -q numpyro@git+https://github.com/pyro-ppl/numpyro
It runs fine, and jax says the GPU is available (if I select that runtime):
import jax
print("jax backend {}".format(jax.lib.xla_bridge.get_backend().platform))
jax.devices()
Currently if I run with num_chains=4 I get the warning that there is only 1 CPU (even in ColabPro).
Is there some way to leverage a single GPU to speedup parallel chains?
I think if you can use MCMC(..., chain_method="vectorized") to take advantage of GPU. But to my experience, it is only fast if num_chains=100 e.g.