Hello,
This may sound strange, but I found that the evolution of kernel lengthscales during a GP regression model training is very different between the newest version of Pyro (1.0.0) and the previous versions (e.g. 0.4.1) for the exact same code on the same dataset.
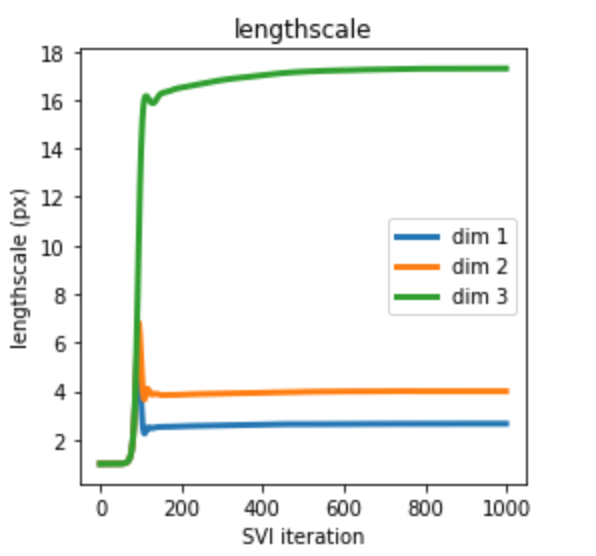
This is evolution of lengthscales for Pyro 0.4.1:
It makes perfect to me sense since we have different lengthscales in our hyperspectral dataset in spatial (dim 1 , dim 2) and energy (dim 3) dimensions.
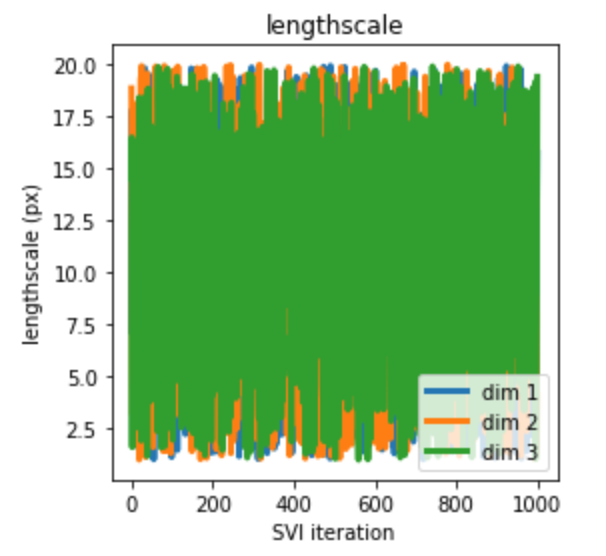
And this is for Pyro 1.0.0:
(exact same code, exact same data)
I don’t quite understand what caused such a drastic difference.
I use sparse GP regression with Matern52 kernel and the following constraints on the lengthscale:
kernel.set_prior(
"lengthscale",
dist.Uniform(
torch.tensor(lscale[0]),
torch.tensor(lscale[1])
).independent()
)
where lscale = [[1., 1., 1.], [20., 20., 20.]]
Thanks in advance!
Hi @ziatdinovmax, I suspect that it is just initial-value issue. In Pyro 1.0.0, initial value is a random value taken from prior. Could you try kernel.lengthscale_map= torch.tensor([1.1, 1.1, 1.1]) to see if that solves the issue?
Sorry for the inconvenience! Btw, do you really need to set initial values to some specific values? If so, would it be useful to do it through self.autoguide method, e.g.
kernel.autoguide("lengthscale", dist.Normal, init_loc=..., init_scale=...)
? Initial values are not important for my usage but I want to hear more opinions from you to improve the interface. 
Thanks for your reply, @fehiepsi! I think I misunderstood the output of spgr.kernel.lengthscale, which I used to make those plots. I thought it shows the learned lengthscales. It seems what I actually need is to take ‘lengthscale_map_unconstrained’ from kernel.state_dict() and transform it to the constrained domain.
Assuming that my new understanding is correct, this part in Pyro’s GP tutorial seems a bit confusing. I don’t think it will actually show us the learned hyperparameters:
The “learned” lengthscale in this case can be very different every run (or determined simply by rng seed):
Excellent! We should have to set_mode to "guide" there. Otherwise, those values are drawn from priors rather than the learned guides. Thanks for pointing it out! I’ll fix it soon.
1 Like
Btw, if you observe something else which is strange, please let me know.
1 Like