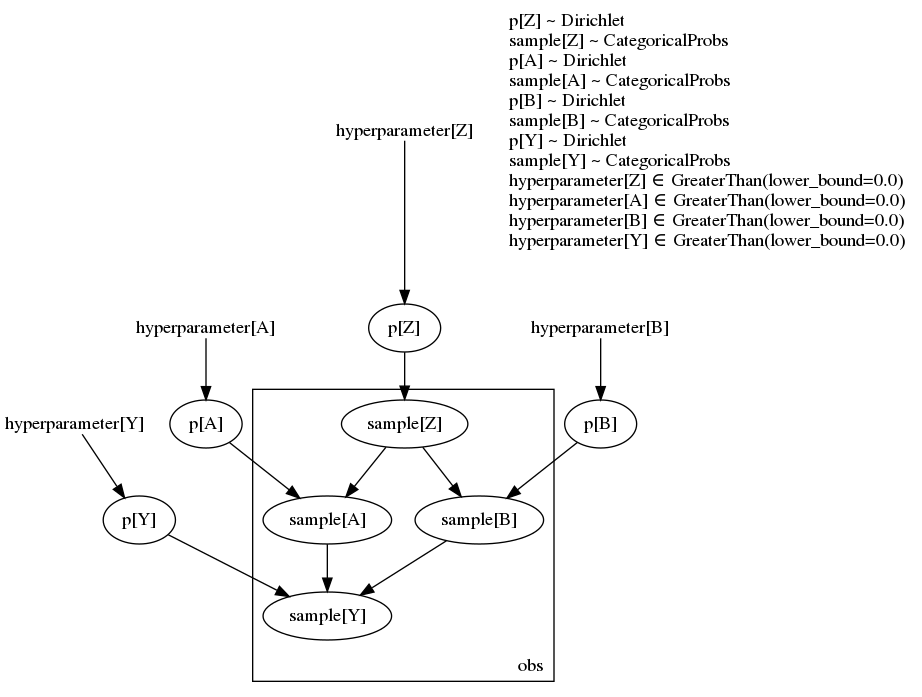
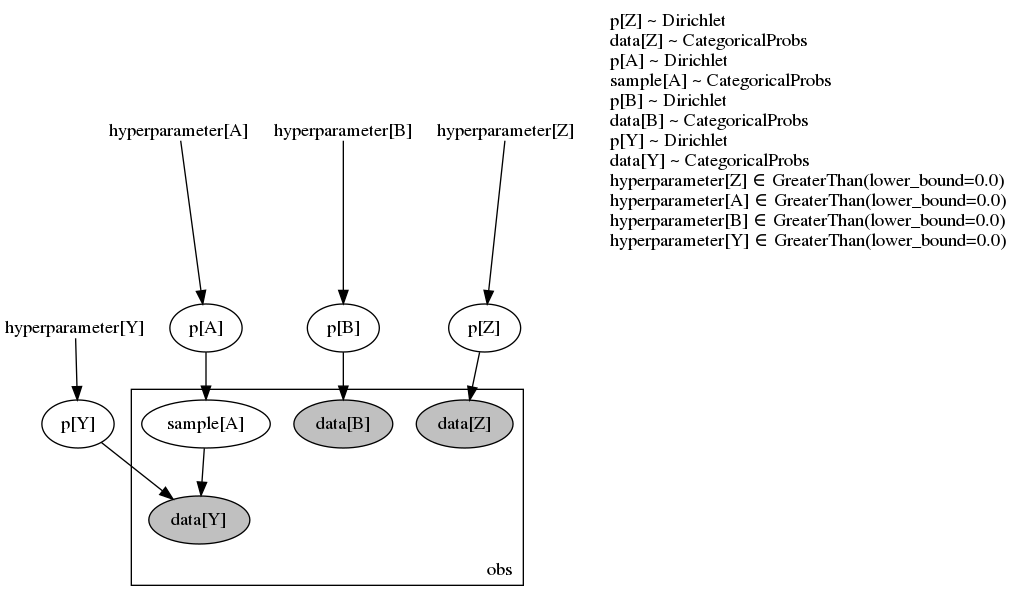
Running MCMC returns reasonable parameters (p[*]) distributions. The thing I’m not confident with is the Predictive samples when using effect handlers, it seems to me that handlers information propagates “downstream” the graph only, e.g.
Predictive(model, samples)(rng_key, **kwargs)['sample[Z]'] # samples is a dict of 'p[*]' from mcmc.get_samples()
yields the same samples, whereas I’d expect that conditioning on B would shift Z's distribution somehow and thus differ from the first two, which should be equal to each other. Replacing Z for Y (descendant of B instead of an ancestor) result in different samples for each query.
Is it clear what I’m struggling with? I’d be happy to share more details if what I provided doesn’t suffice to diagnose any problems. Thanks in advance.
i don’t know if i understand your question but if you only do inference once and obtain a single samples then you’ve done inference precisely once for one specific model. condition does not go in and do inference; it fixes a latent variable to be a particular value (makes it observed).
That’s what I’m trying to do. I’ll try to explain a bit further, I might be missing something:
Running MCMC passing data from Z, B and Y return samples for p[Z], p[B], p[Y] and also p[A] and sample[A] (data from A is sampled since it’s a latent variable). Ultimately, what I’m interested in p[Z], p[B], p[Y] and p[A], that’s what I store in samples (note that sample[A] I do not).
Then I’ll try to make inference. What I expect is:
Predictive(model, samples)(rng_key, **kwargs) to return samples from sample[Z], sample[A], sample[B] and sample[Y], that is, the sampled data conditioned on the parameters which are stored in samples
Predictive(do(model, {'sample[B]': jnp.array([0])}), samples)(rng_key, **kwargs) also to return samples from sample[Z], sample[A], sample[B] and sample[Y], but this time for Y matters (B’s only descendant), sample[B] is equal to 0 regardless of the actual sample[B]
and
Predictive(condition(model, {'sample[B]': jnp.array([0])}), samples)(rng_key, **kwargs), again, to return samples from sample[Z], sample[A], sample[B] and sample[Y], but now for sample[B] to be an array of zeros (which it is), and the distribution of the nodes dependent of B to change somehow, that is, conditioned on the “sampled value of B” (sample[B]), which is fixed to 0, shouldn’t it’s ancestor distribution differ from the unconditional query? That change is what I’m not seeing.
can you please create a minimal working example to illustrate precisely what you mean? for example i don’t know what “Running MCMC passing data from…” means. words can be confusing if each person has their own private language. code is unambiguous.
@acacio sorry for the slow response but can you please create a truly minimal example? absolutely simple models where you describe the result you get and what you expected instead.
these code paths are not exactly simple: n = data[list(latent.keys())[list(latent.values()).index(False)]].size if data else n
dependencies on networkx should not be necessary here…
please note that condition basically takes a sample statement without an obs keyword and turns it into a sample statement with an obs keyword. it does not do inference; it performs a program/model transformation.
i’m afraid i can’t answer your question as it stands because i don’t really understand the models and the queries you’re making.
I failed to realize that at first, I guess it became clearer after some thought.
Given the following DAG
Z → B
What I was trying to query, in terms of probabilities, was P(Z | B = 1) and contrast with P(Z | do(B = 1)), for instance. But as you said, conditioning is not doing inference, it just fixed the value of B, and propagated downstream the network. Thus, effectively yielding the same samples as with the do handler.
I’m still not sure how to best query P(Z | B = 1), that is, after “learning the parameters” of a model, how do I query the probability of a variable, given I know the value of another.
The turnaround I resorted to was to sample the model - passing to predictive the parameters sampled from an MCMC run given data - and then filter the samples leaving only the ones compatible with the evidence (B = 1). From that, the sampled parameters that lead to the realizations of Z should be the approximate distribution of P(Z | B = 1). Does that rational seems correct?
I will try to code that in a simpler example and leave it here for checking and maybe future reference.
Although in practice that model may be of none use, I just thought an explicit implementation of a BN would be a good way of gaining some traction with PPLs before trying anything more complex, personally, I think it’s proving to be fruitful, thanks for sticking with me and trying to help!