Hello. I have been playing around with hierarchical models, and am investigating building them a modular way, with the “single object” model being a black box that the hierarchical model wraps around. i.e., when already equipped with some model for a single source with priors equipped with adjustable parameters \Lambda:
I want to be able to easily model a population of k such sources in a hierarchical way without making changes to the single source model:
I know that such modelling is typically performed by concatenating the data into a single input and using some clever indexing, but there are some cases where this approach is not suitable. I am looking to create a generic hierarchical model that can run over a list of x's to model the entire population.
As a toy example, consider the problem of estimating the mean and variance \mu_k,\sigma_k of k groups of data, where each group has a varying number of samples, provided we know that \mu_k and \sigma_k follow the same distribution across the population:
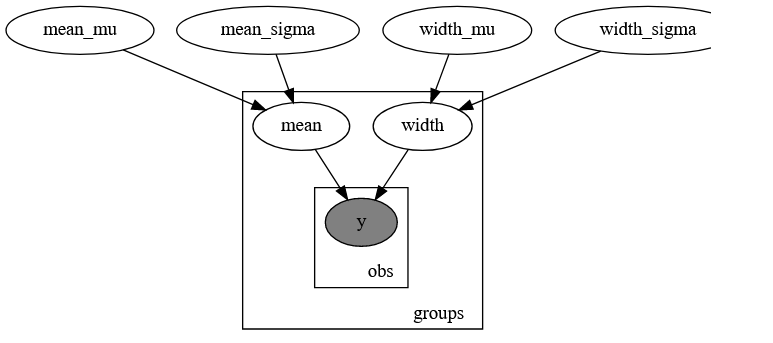
I have found a workaround for this toy case by using the scope handler and a for loop, but this is a clumsy workaround and extremely slow. I’ve seen some examples of calling the plate index like an enumerator, but have had no luck doing this myself.
def model_single(data, prior_params = {'mean_mu': 0.0, 'mean_sigma': 5.0, 'width_mu': 0.5, 'width_sigma': 5.0, } ):
'''Model for a single group'''
mean_mu, mean_sigma = prior_params['mean_mu'], prior_params['mean_sigma']
width_mu, width_sigma = prior_params['width_mu'], prior_params['width_sigma']
tdist = dist.TransformedDistribution(
dist.Normal(width_mu, width_sigma),
dist.transforms.SoftplusTransform(),
)
width = numpyro.sample('width', tdist)
mean = numpyro.sample('mean', dist.Normal(mean_mu, mean_sigma))
with numpyro.plate('obs', len(data)):
numpyro.sample('y', numpyro.distributions.Normal(mean,width), obs = data)
#-------------------------------------------
# Run a plate of model_single over a list of 'data' inputs 'DATA'
def model_many(DATA):
'''A terrible workaround but correct likelihoods'''
mean_mu = numpyro.sample('mean_mu', dist.Uniform(-10,10))
mean_sigma = numpyro.sample('mean_sigma', dist.Uniform(0.0,10))
width_mu = numpyro.sample('width_mu', dist.Uniform(0.0,10))
width_sigma = numpyro.sample('width_sigma', dist.Uniform(0.0,10))
for i, data in enumerate(DATA):
with numpyro.handlers.scope(prefix="%i" %i, divider = "_"):
model_single(data, prior_params = {'mean_mu': mean_mu, 'mean_sigma': mean_sigma, 'width_mu': width_mu, 'width_sigma': width_sigma, })
def model_many(DATA):
'''Doesn't work, cannot use plate index as array index'''
mean_mu = numpyro.sample('mean_mu', dist.Uniform(-10,10))
mean_sigma = numpyro.sample('mean_sigma', dist.Uniform(0.0,10))
width_mu = numpyro.sample('width_mu', dist.Uniform(0.0,10))
width_sigma = numpyro.sample('width_sigma', dist.Uniform(0.0,10))
with numpyro.plate('groups', size = len(DATA)) as i:
data = DATA[i]
model_single(data, prior_params = {'mean_mu': mean_mu, 'mean_sigma': mean_sigma, 'width_mu': width_mu, 'width_sigma': width_sigma, })
Please advise the best practice for approaching this case, and my apologies if I have missed something obvious.