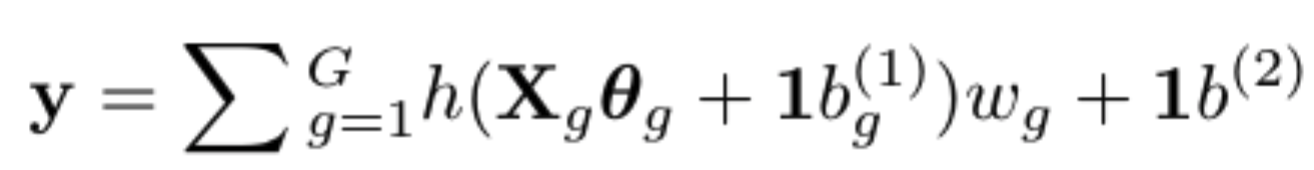Could someone help me understand how to set a unit normal prior over my bias terms (b1 and b2) ? Is this correct? I want to ensure my weights and biases are updating once HMC starts.
looks ok to me. it’s unfortunate you removed the many assert statements found in examples/bnn.py because that could have helped you be confident in your model specification.
Hello Martin! Wonderful, I will add those back in. Why are bias terms not added in the BNN example? From a neural network perspective, those are present (but not required) in the general case. I realize this could have been a user choice.
just for simplicity. and it wasn’t required to get a decent fit on that fake dataset. also because that example isn’t intended to motivate people to run hmc on neural networks with millions of parameters. which isn’t going to work out of the box, to say the least.
Yes this makes sense. Is there a way to speak with someone 1-1 to discuss my use case with numpyro? I am building a BNN with HMC sampling where I have (in my current dataset) about 40K parameters. I get good performance on several of my simulated data examples, whereas for others my method does poorly.