Hi, I am trying to implement a 1-d Gaussian Mixture of two components with Relaxed Bernoulli (binary case of concrete/gumbel-softmax) as the variational posterior.
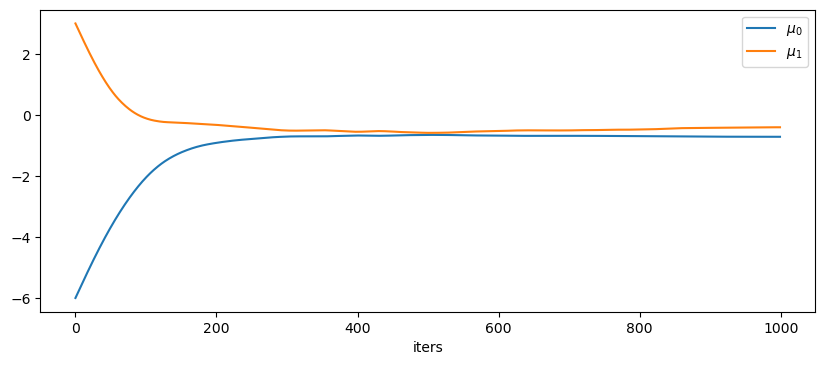
However, the model cannot converge to the correct result:
p = 0.6
n_sample = 1000
mask = dist.Bernoulli(probs=p).sample((n_sample,))
loc1, loc2 = -6.0, 3.0
scale = 0.5
data = dist.MaskedMixture(mask.bool(),
dist.Normal(loc1, scale),
dist.Normal(loc2, scale)).sample()
def model(data):
weights = pyro.param('weights', torch.tensor(0.5))
locs = pyro.param('locs', torch.randn(2,))
with pyro.plate('data', len(data)):
assignment = pyro.sample('assignment', dist.Bernoulli(weights)).long()
pyro.sample('obs', dist.Normal(locs[assignment], 1.0), obs=data)
T = 0.5
def guide(data):
with pyro.plate('data', len(data)):
alpha = pyro.param('alpha', torch.rand(len(data)), constraints.unit_interval)
pyro.sample('assignment', dist.RelaxedBernoulliStraightThrough(torch.tensor(T), probs=alpha))
def train(data, svi, num_iterations):
losses = []
pyro.clear_param_store()
for j in tqdm(range(num_iterations)):
loss = svi.step(data)
losses.append(loss)
return losses
def initialize(seed, data, model, guide, optim):
pyro.set_rng_seed(seed)
pyro.clear_param_store()
svi = SVI(model, guide, optim, Trace_ELBO(num_particles=50))
return svi.loss(model, guide, data)
n_iter = 500
pyro.clear_param_store()
optim = Adam({'lr': 0.1, 'betas': [0.9, 0.99]})
loss, seed = min(
[(initialize(seed, data, model, guide, optim),seed) for seed in range(100)]
)
pyro.set_rng_seed(seed)
svi = SVI(model, guide, optim, loss=Trace_ELBO(num_particles=50))
losses = train(data, svi, n_iter)
pyro.param('locs')
Out[50]:
tensor([-0.9745, -0.4087], requires_grad=True)
Is there any way for debugging this model or solving this issue? ( I believe this is caused by local minima problem if my implementation is correct.)