I need some help with understanding when to use the output of the Bayesian neural network and when I can use the observations (I guess, one can replace NN with regression in this question).
The data (toy one) is in reals and the BNN ends with something like this (my net defined with random_flax_module):
If I want to evaluate the model’s rmse, then it doesn’t matter whether to use obs or mu (as long as I have enough samples), that’s clear. If I want to compute the test log-likelihood then I use mu and sigma (i.e. \log \text{Norm}(y_{test} | \mu, \sigma)).
But what should I use if I want to compute the quantiles and obtain credible intervals/empirical coverage? I am guessing that the answer is “it depends” but then on what and what am I estimating in each case, what is the terminology?
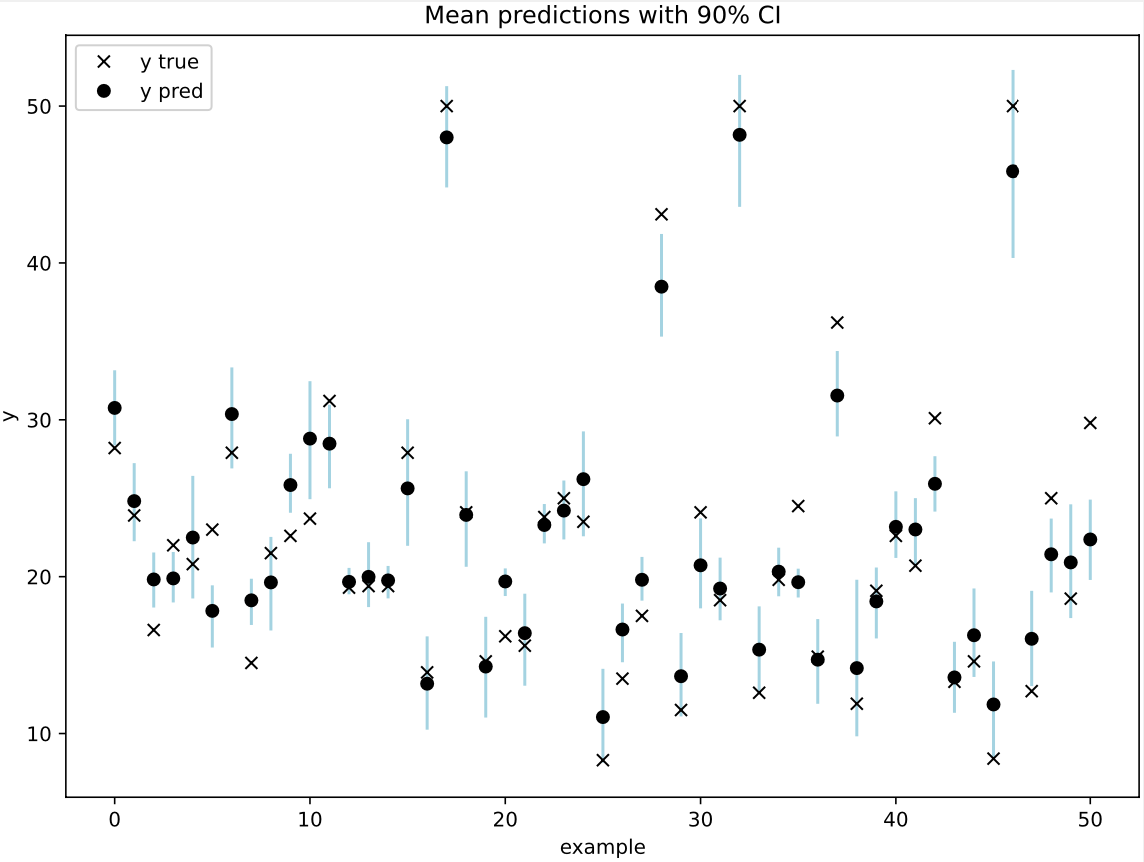
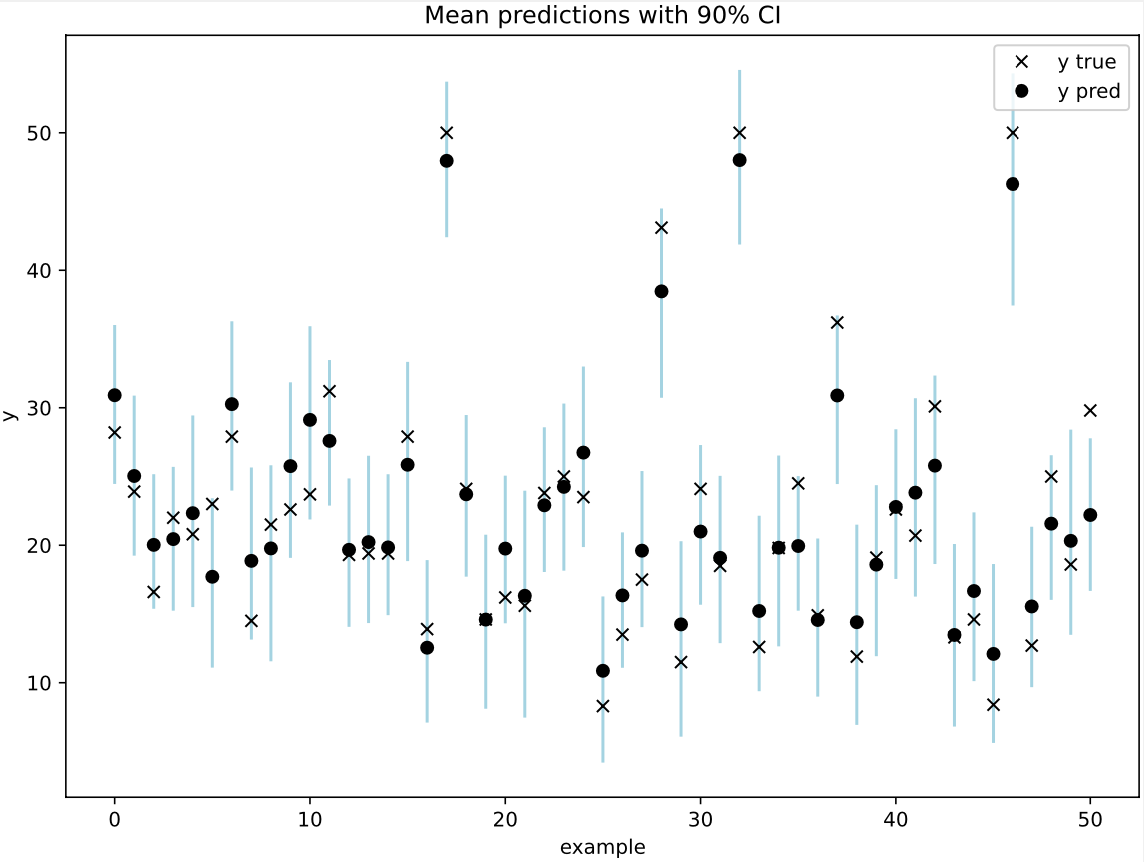
E.g. in this example observations are used for the plot.
And here the output of the network is used.
Any help is appreciated! Would be especially good to find a good resource/particular book’s chapter…
Ah, on slightly more reflection, I realized what you’re asking is more nuanced.
Suppose our model is:
Y = g(X, W) + E
Y is our target, X is our covariates/features, W are the net parameters, g is the neural network function and E is the noise random variable.
You’re asking if on some new X (call it X’), whether our prediction of Y’ should be g(X’, W) or g(X’, W) + E.
To be statistically coherent, the prediction/credible interval of Y should be based on the latter. However, often the noise model E is assumed to have zero mean and a fixed variance, so you can get away with just looking at the mean function g(X’, W), especially when you’re focused on your best estimate of the expectation of Y’. But, if E varies with X or if it’s distribution has additional hyperparameters, then your complete prediction interval for Y’ should account for samples from E.
Thanks a lot for your reply! (The first one was confusing - I understand how BNNs work, how to perform inference, how to get posterior predictive etc…)
Exactly, that’s my question! Alternatively, to correspond to the code can write g(X', W) or \text{Norm}(g(X', W), E).
What I also understand is that for obtaining posterior predictive’s mean in practice, it shouldn’t really matter (and so it doesn’t matter anything like rmse). However, it does matter for standard deviation and credible intervals (in their Bayesian sense) - hence my question.
(Apologies again for mis-judging your level of understanding!)
For your code sample, if you’re using the base sampling methods, I think you want to follow the first example to get samples of Y’ that account for the noise model. I believe that’s correct (especially for fancier noise models).
Reading the SteinVI example, it feels to me like a bug that the mean function gets used for the predictions. But I don’t know anything about the SteinVI module.
As expected, I visually observe larger prediction intervals and greater coverage. I don’t know anything about SteinVI, so perhaps the authors can correct me if doing this has some logical issues under this procedure.
@jbajwa Yes, thanks a lot! It does make sense since the model adds prec_obs = numpyro.sample("prec_obs", Gamma(1.0, 0.1)) to the intervals.
I guess that a similar effect would have happened with MCMC, though SteinVI as a VI method could be underestimating the intervals for y_pred more…(unsure)
I’m sorry for confusing you about credible intervals. There is nothing special about SteinVI with regards to computing the credible interval, and using the means is simply a bug (as @jbajwa points out). I wrote the example for RMSE and added the credible interval visualization afterward. However, I didn’t think of correcting it for modeling noise. I’ll update the example.