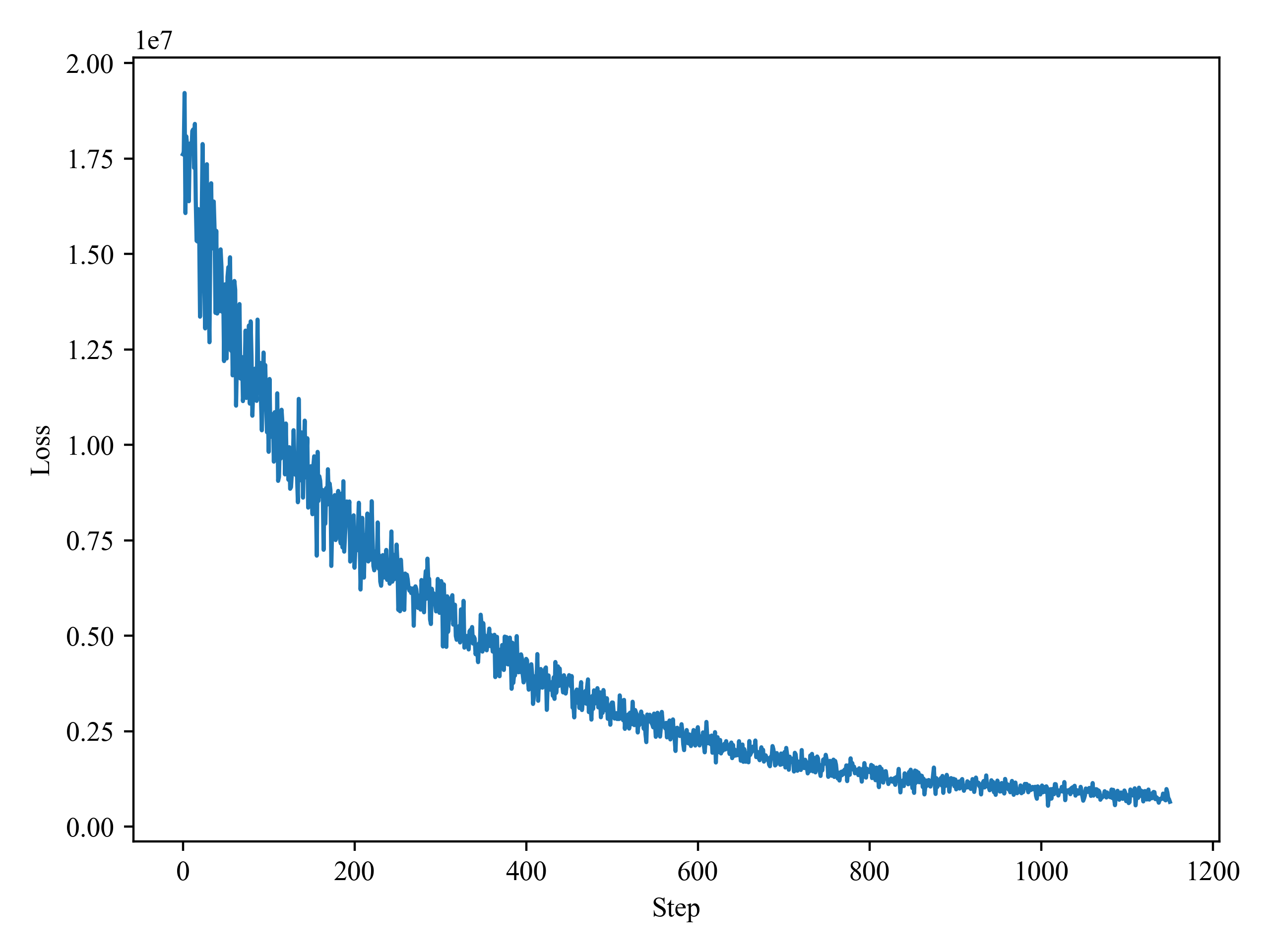
Hello, I’m building an HMM topic model. I have implemented my model via Pyro. Before applying my model to the real dataset, I did a synthetic experiment, in which I generated a batch of synthetic data by using known parameters. The model is then trained using this data to evaluate the recovery of the parameters. The model runs very smoothly in terms of the Loss curve:
Then I compared the reproduction of some of the parameters and found that some of them were almost perfectly reproduced, but others were completely different from the real values:
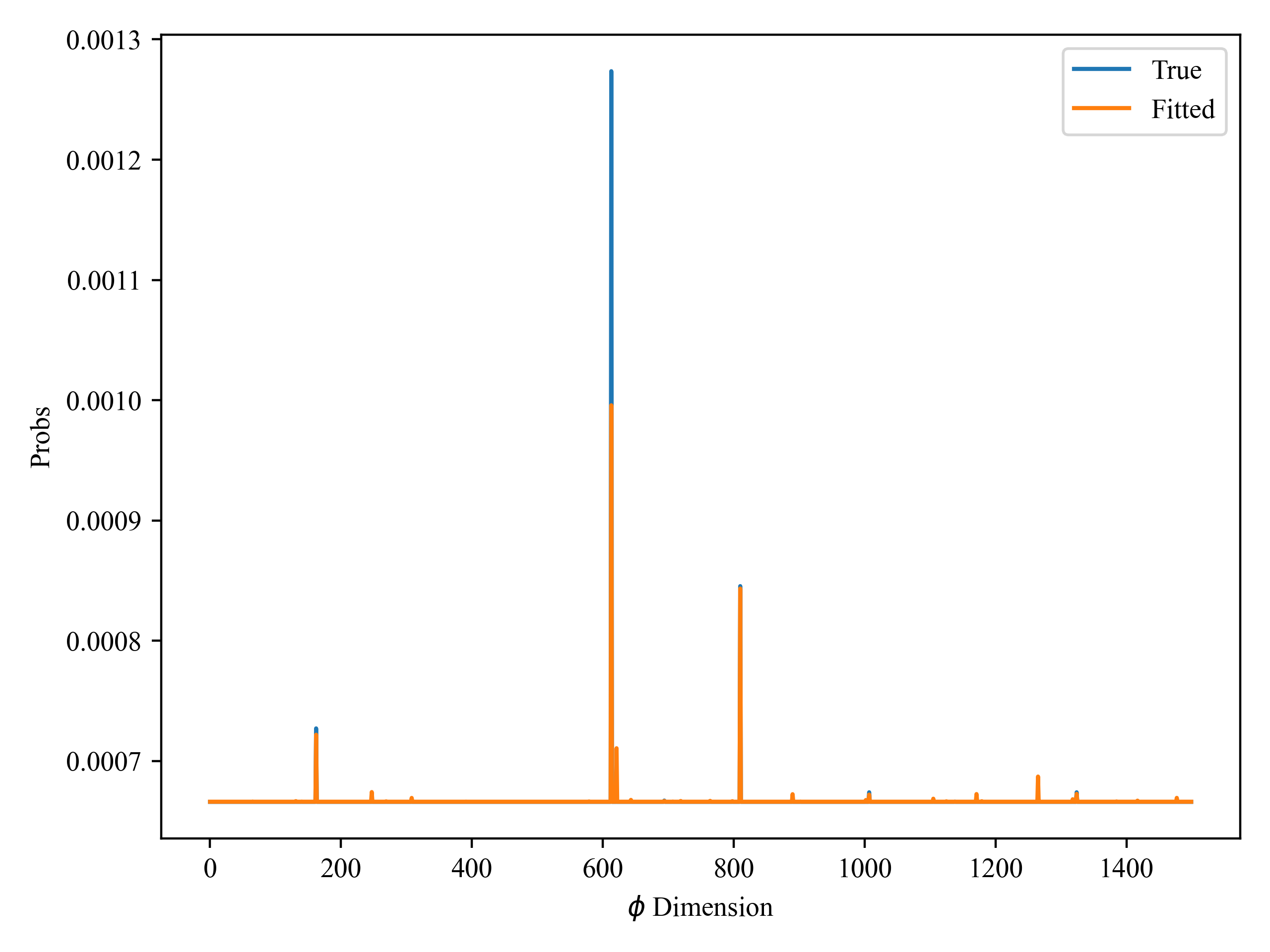
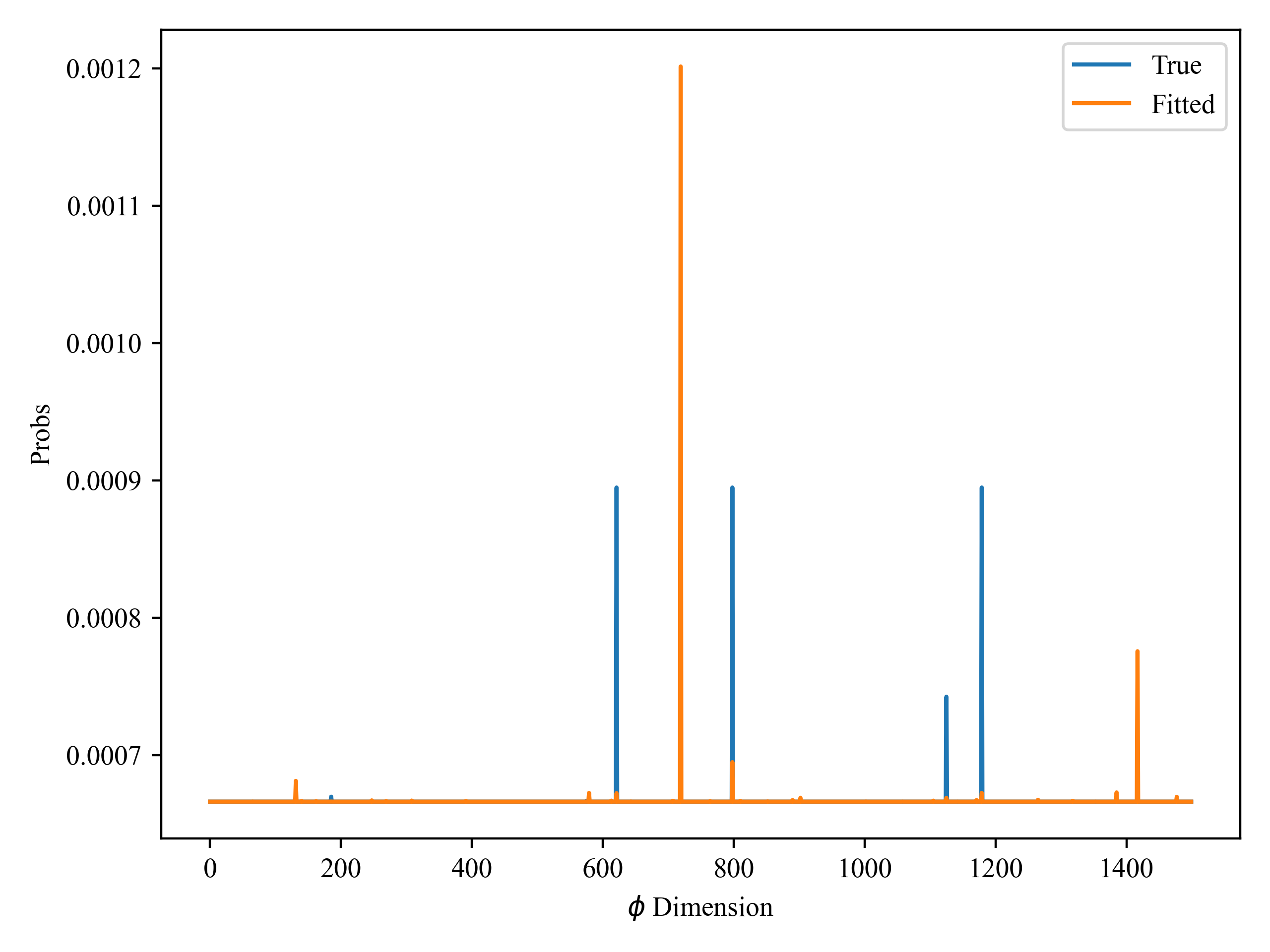
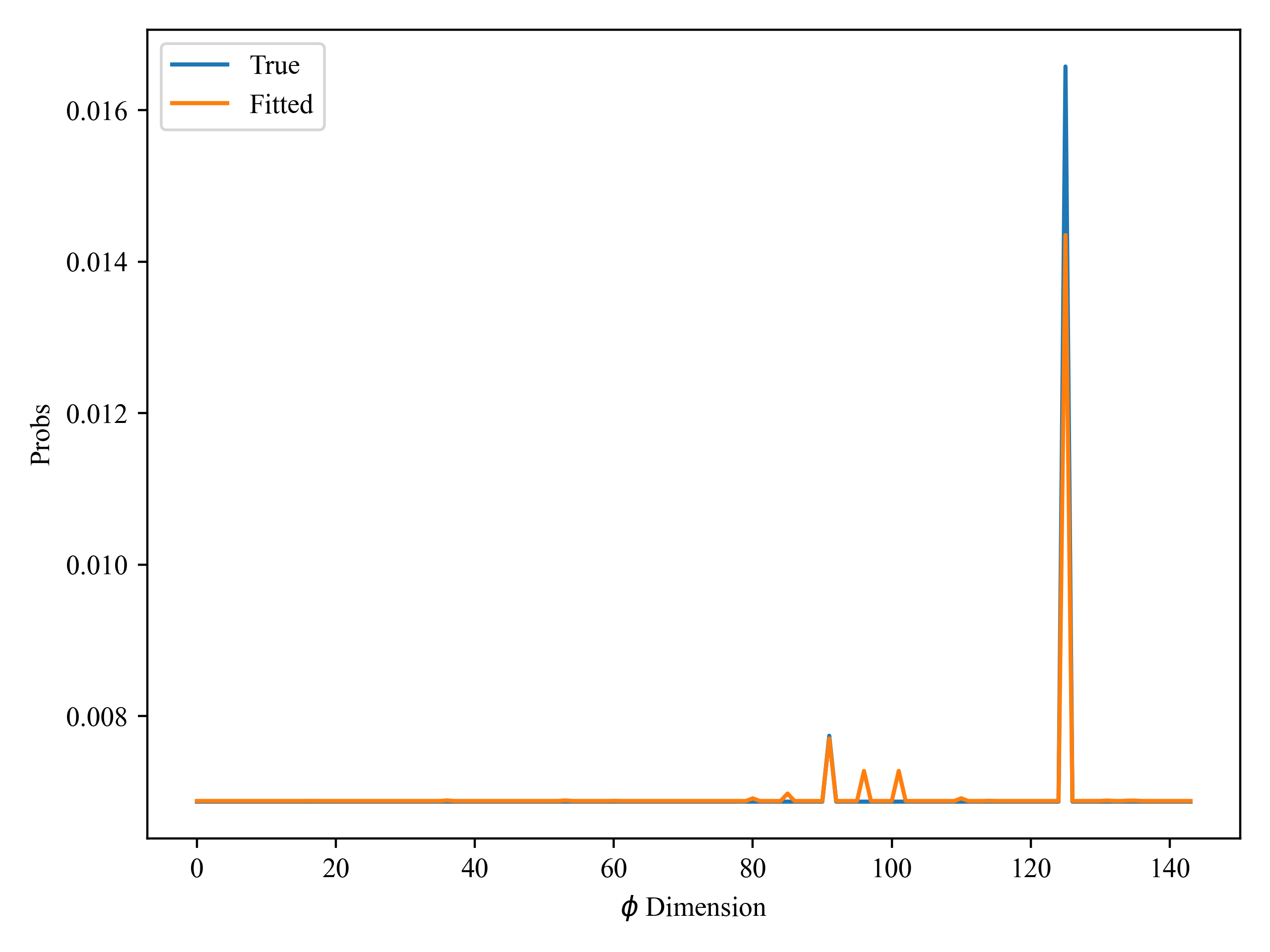
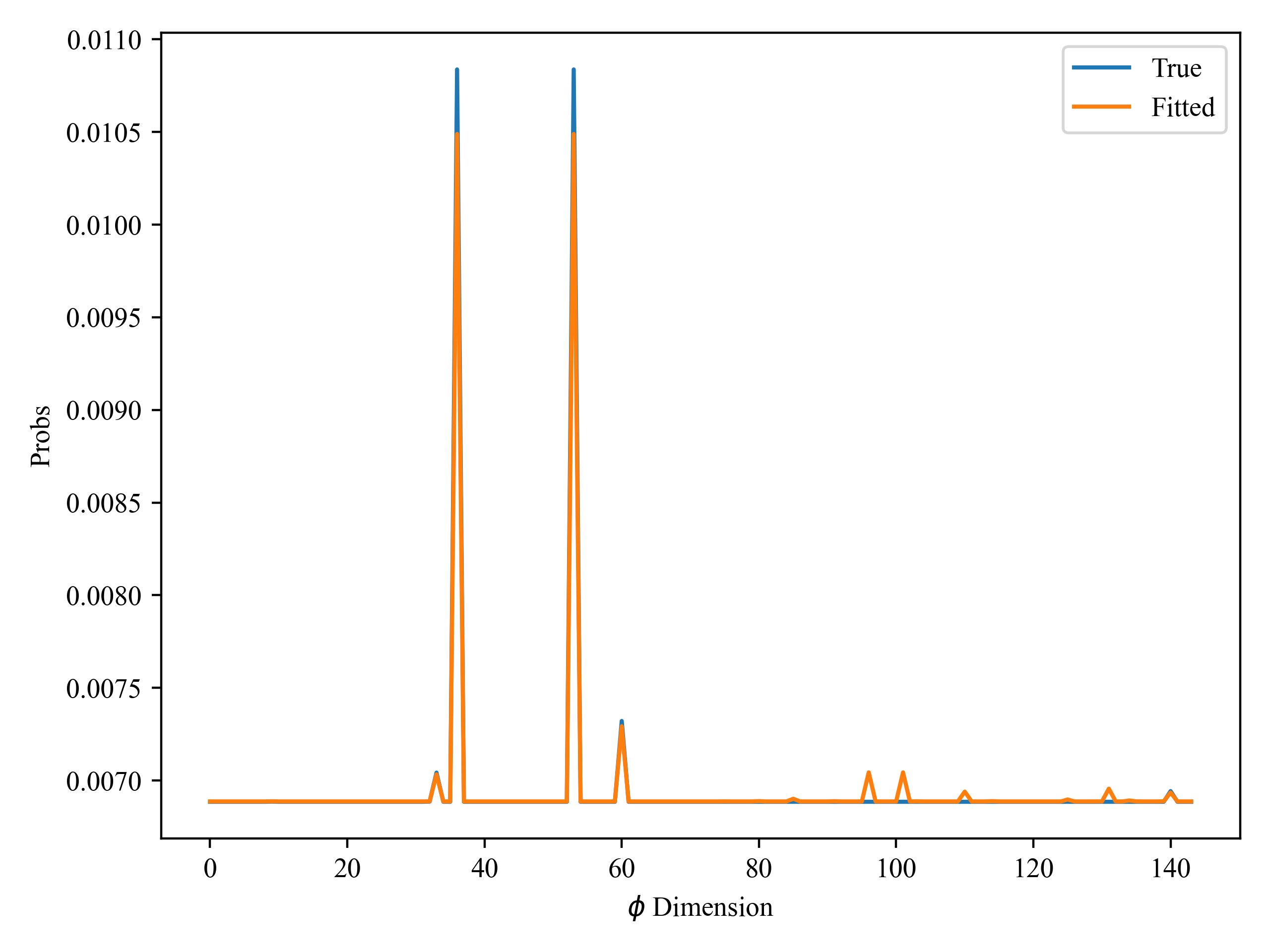
These parameters are the distribution of topics (here I call it motivation), and the number of topics I specify manually is 10. I used the guide
AutoDelta and I don’t know if this result is enough to prove that my program is correct and the model is valid.
Regarding those results with large differences from the real values, I currently think of the following possible reasons:
- the
Batch_sizeof the synthetic data is too small, the currentBatch_sizeis 2500; - the artificially specified parameters are unreasonable, one of the hidden variables in my model is a shape of
(Topic_num, Hidden_state_num, X)continuous random variable, the specific why of each sample’stopic assignmentwill directly depend on this variable, but some hidden state corresponding to the value under the dimension may be too large, resulting in the generated data does not cover all the Topics; -
AutoDeltamay not be enough to train this complex model. I triedAutoNormal, but encountered errors withSimplex()constraints. -
Learning rateis unreasonable,ClippedAdamwithinit_lr=1e-2andgamma=0.1is applied to my model. The totalSVI stepsis set to 1200.
I hope I can get your advice, thank you very much.