Hello, I am working through the Bayesian Hierarchical Linear Regression Numpyro tutorial. In short, the individual linear regression parameters (𝛼_i, 𝛽_i) come from the common group distributions parameterized by (𝜇_𝛼, 𝜎_𝛼, 𝜇_b, 𝜎_𝛽).
After the parameters are learned, the posterior mean of 𝛼 is much higher than that of 𝜇_𝛼.
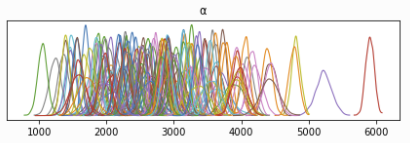
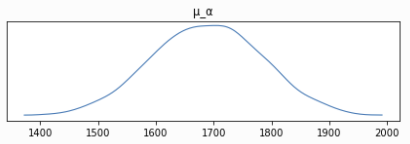
If 𝛼_i is from N ~ (𝜇_𝛼, 𝜎_𝛼), why is the posterior 𝜇_𝛼 (mean = 1691) not near the mean posterior 𝛼_i (mean = 2764)? Thanks!