Hello!
It’s here better way to apply transform function to the data?
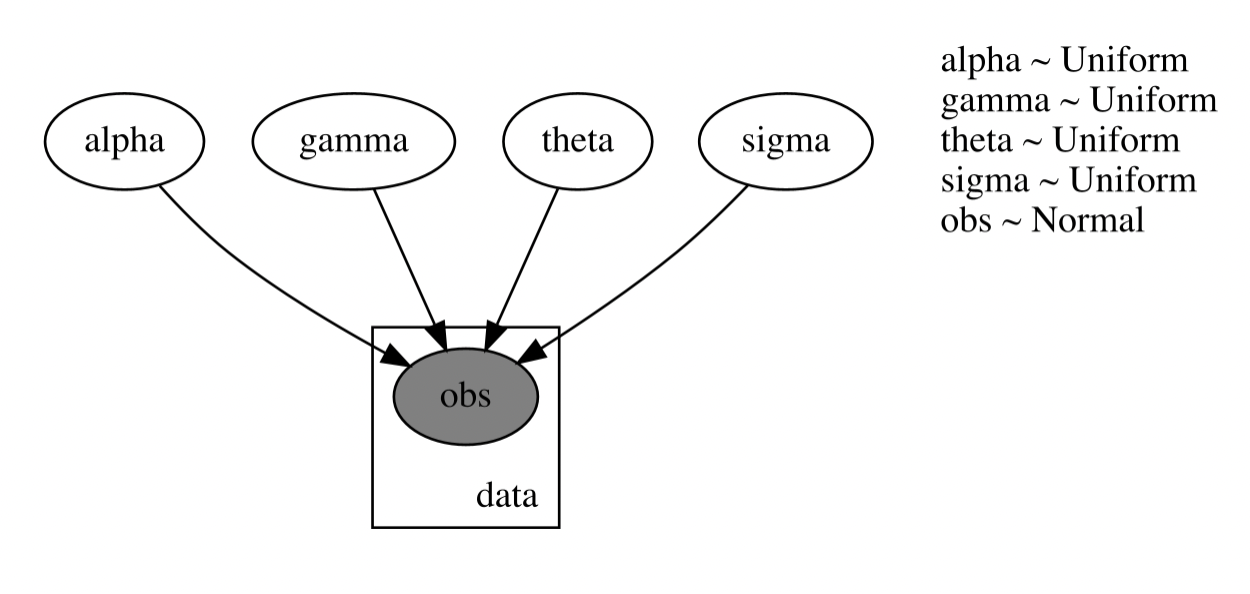
I have to define model using explicit loop and unnecessary sigma to find theta:
def adstock(x, y):
theta = pyro.sample('theta', dist.Uniform(0.1, 1))
sigma = pyro.sample('sigma', dist.Uniform(0, 1))
d = 0
z = np.zeros(x.shape)
for i in range(len(x)):
d = x[i] + theta*d
z[i] = pyro.sample(f"obs_{i}", dist.Normal(d, sigma), obs=y[i])
And it works quite slowly.
I want to add this as part of another model like that:
def adstock(x, theta):
d = torch.tensor(0)
y = torch.zeros(x.size())
for i in range(x.size(0)):
d = x[i] + theta * d
y[i] = d
return y
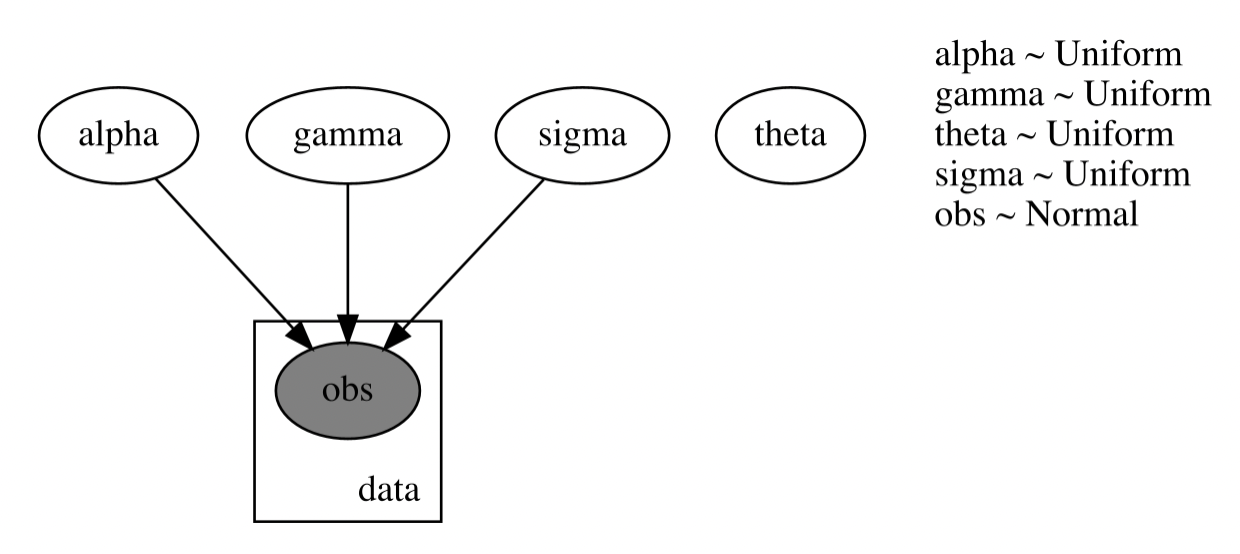
def mix(x, y):
alpha = pyro.sample('alpha', dist.Uniform(0.1, 10))
gamma = pyro.sample('gamma', dist.Uniform(0.1, 1))
theta = pyro.sample('theta', dist.Uniform(0.1, 1))
adstock_x = adstock(x, theta)
s_curved = s_curve(adstock_x, alpha, gamma)
sigma = pyro.sample("sigma", dist.Uniform(0., 1.))
with pyro.plate("data", len(s_curved)):
pyro.sample("obs", dist.Normal(s_curved, sigma), obs=y)
But in this case I can’t link theta to the model:
Please help me understand better how to deal with pyro and find good solution
Thank you in advance!