Hello, can you please explain why the SVI inference fails to find a proper solution in GMM tutorial if we change the assigment local RVs from Categorical to Bernoulli:
K = 2 # Fixed number of components.
def model(data):
# Global parameters.
weights = pyro.param('weights', torch.FloatTensor([0.5]), constraint=constraints.unit_interval)
locs = pyro.param('locs', 10 * torch.randn(K))
scale = pyro.param('scale', torch.tensor(0.5), constraint=constraints.positive)
with pyro.iarange('data', len(data)):
# Local variables.
assignment = pyro.sample('assignment',
dist.Bernoulli(torch.ones(len(data)) * weights))
pyro.sample('obs', dist.Normal(locs[assignment.to(torch.int64)], scale), obs=data)
def guide(data):
with pyro.iarange('data'):
# Local parameters.
assignment_probs = pyro.param('assignment_probs', torch.ones(len(data)) / K,
constraint=constraints.unit_interval)
pyro.sample('assignment', dist.Bernoulli(assignment_probs), infer={"enumerate": "sequential"})
The GMM tutorial is very sensitive to initial conditions; it only converges to a correct solution for some random seeds. My guess is that your Bernoulli example still finds a good solution for some seeds.
I’d really like to fix this aspect of the GMM tutorial, but I haven’t found a parsimonious fix that keeps the tutorial simple and focused on enumeration. @areshytko Do you have any suggestions? Some options I’ve considered are:
Trying random restarts if the solution appears to be degenerate. This would require a degeneracy criterion.
Proposing many more components than needed; then merging and pruning down to a small number. However this is succeptible to learning one component per data point.
Divisive hierarchical clustering with a heuristic to split on the largest eigenvector at each step.
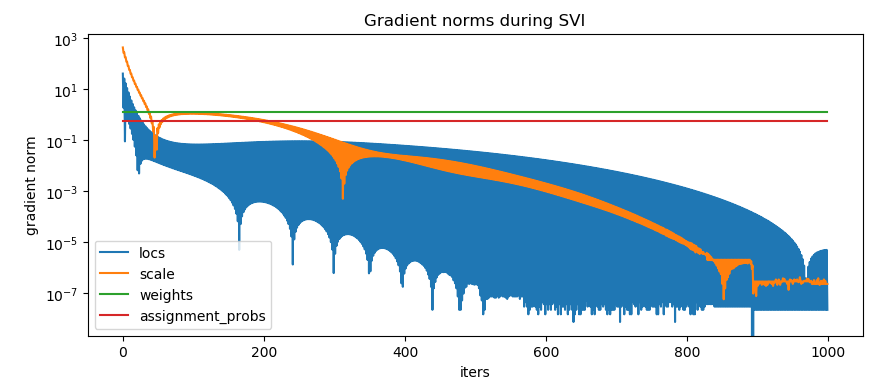
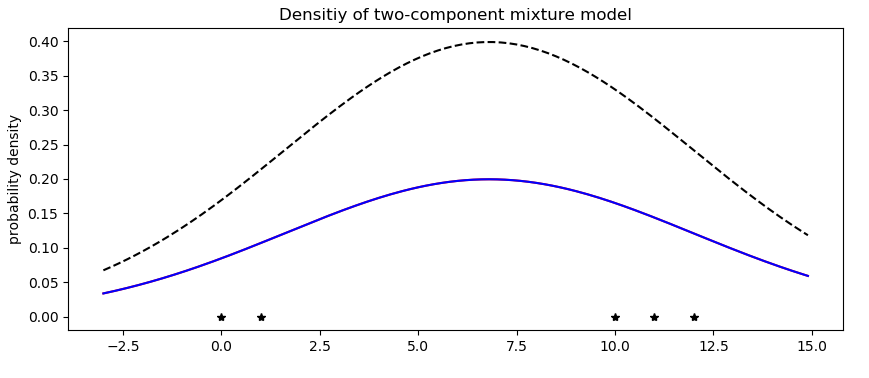
@fritzo, thank you for the reply. Actually, even if we give good initial conditions for cluster centroids: 10 and 1, it still converges to a solution where it tries to describe everything with a single gaussian. And doesn’t touch weights and locations at all during inference…
The point is: it’s one of the simplest possible models where we can even compute exact E step, and we only have 5 1d data points. Why the inference is so sensitive to random seeds?